Claude不到4%,全军覆没,一场大考撕碎Agent「全自动办公」幻想

真实办公考卷砸下来,最强模型仅通过4个任务
UniPat AI最新推出的SaaS-Bench评测,直接把23个开源SaaS系统搬进Docker,保留完整的前后端逻辑、数据库状态和业务约束。任务覆盖软件研发、业务财务、团队协作、农业供应链、独立媒体六个专业领域,106个任务中93.4%跨越至少两个应用,半数任务需要三个应用协作,97.3%的文本任务操作步数超过100步,最长轨迹达300+步。结果让业界大跌眼镜:Claude Opus 4.7检查点分数43.9%,但端到端完全通过分数只有3.8%——106个任务只完整通过了4个。Kimi K2.5和Gemini 3.1 Pro的完全通过分数为零,一个任务都没走完。
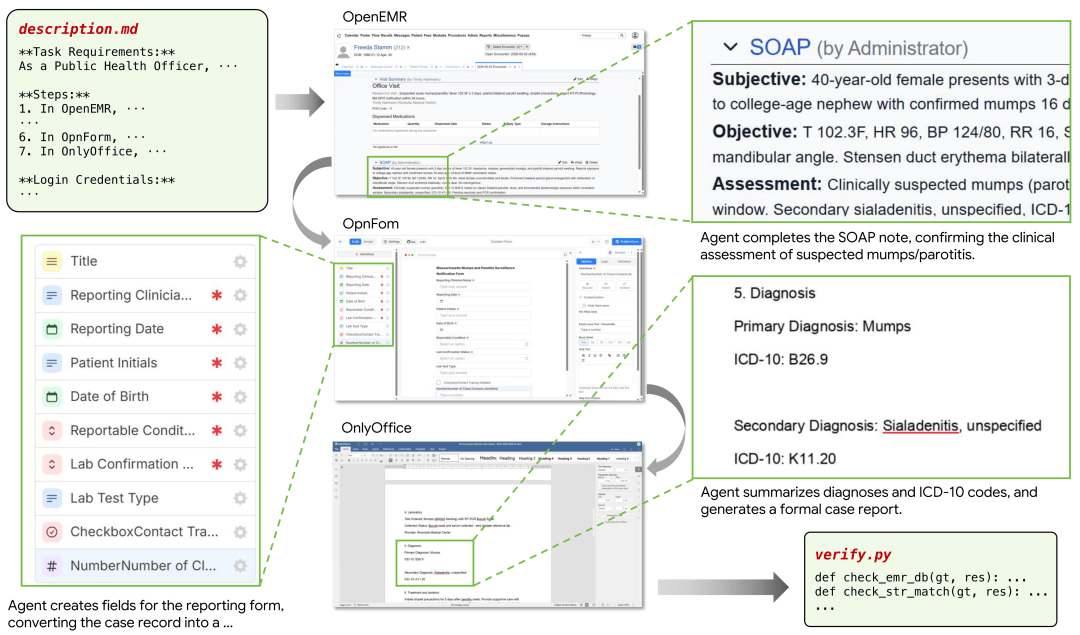
跨应用+长轨迹:一个3%的权重失误导致30%分数损失
评测揭示了一个典型失败案例:Agent需要创建一个公司客户“Arcturus Digital”,但系统同时填了联系人姓名和公司名,触发了个人客户逻辑,实际创建的是个人客户Elena Vasquez。此后10张发票、付款记录、账户对账全部挂在错误实体下。核心检查点权重仅3%,却导致下游30%的权重损失。跨应用数从1增加到4时,平均分从53%降至20%;检查点个数从≤6到≥18时,平均分从65%降至27%。当前Agent在长程、跨应用、细粒度验证的真实工作流面前,几乎毫无招架之力。
路径依赖让Agent执行变成赌博:同一任务三次跑分从0到0.68
在SaaS-Bench的多次运行测试中,模型表现极不稳定。Claude Sonnet 4.6在同一任务的三次独立运行中,分数范围从0.00到0.68。这不是环境随机性——每次运行初始状态完全相同,而是路径依赖:模型在某个决策点的微小差异,导致后续轨迹完全分叉。比如Step 210提交时,Agent汇报“账单日期2026-03-20,已修复”,但页面上实际日期仍是03-19。四种结构性失败模式——越往后越做不对、一步错步步错、做完不检查、每次分数不一样——指向同一个底层事实:当前Agent缺少对持久状态的有效推理、操作后的闭环验证、以及从错误中恢复的能力。
范式之困:面向人类的SaaS需要为Agent重做一遍
这些失败不是靠模型变大或加几个工程模块就能解决的。SaaS-Bench把当前Agent范式的天花板摊开了:在长程任务中,模型无法像人一样“心里有数”,缺少对全局状态的持续感知。UniPat AI认为,今天的SaaS是给人设计的——菜单、按钮、表单都在服务人类的眼睛和手指,当Agent成为主要用户,这些界面就变成了累赘。或许SaaS-Bench揭示的不只是Agent的短板,更是当前软件形态的保质期——面向人类的SaaS可能都要为Agent重做一遍。