Claude Mythos官宣:性能碾压Opus 4.6,因太危险遭「囚禁」

背景:意外泄露引爆AI界
Claude Mythos,代号「Capybara」,是Anthropic开发的最高层级AI模型,原本处于严格保密状态。然而,上个月因公司内容管理系统配置失误,导致包含模型训练结果、测试数据及项目计划的内部资料被意外曝光,引发全网热议。泄露的内容揭示了Mythos在编程、推理和网络安全方面远超现款旗舰模型Claude Opus 4.6,甚至具备自主发现数千个高危零日漏洞的能力。
- 模型代号:Capybara
- 状态:尚未正式发布
- 意外原因:人为配置错误
- 涉及平台:内部CMS系统因外部工具配置失误泄露数据
这一泄露事件被《财富》杂志捕捉到,直接引爆科技界对AI安全与能力边界的讨论。
性能碾压:多项测试远超现有模型
Claude Mythos在多个专业任务中的表现大幅超越Claude Opus 4.6。以下是部分测试成绩对比:
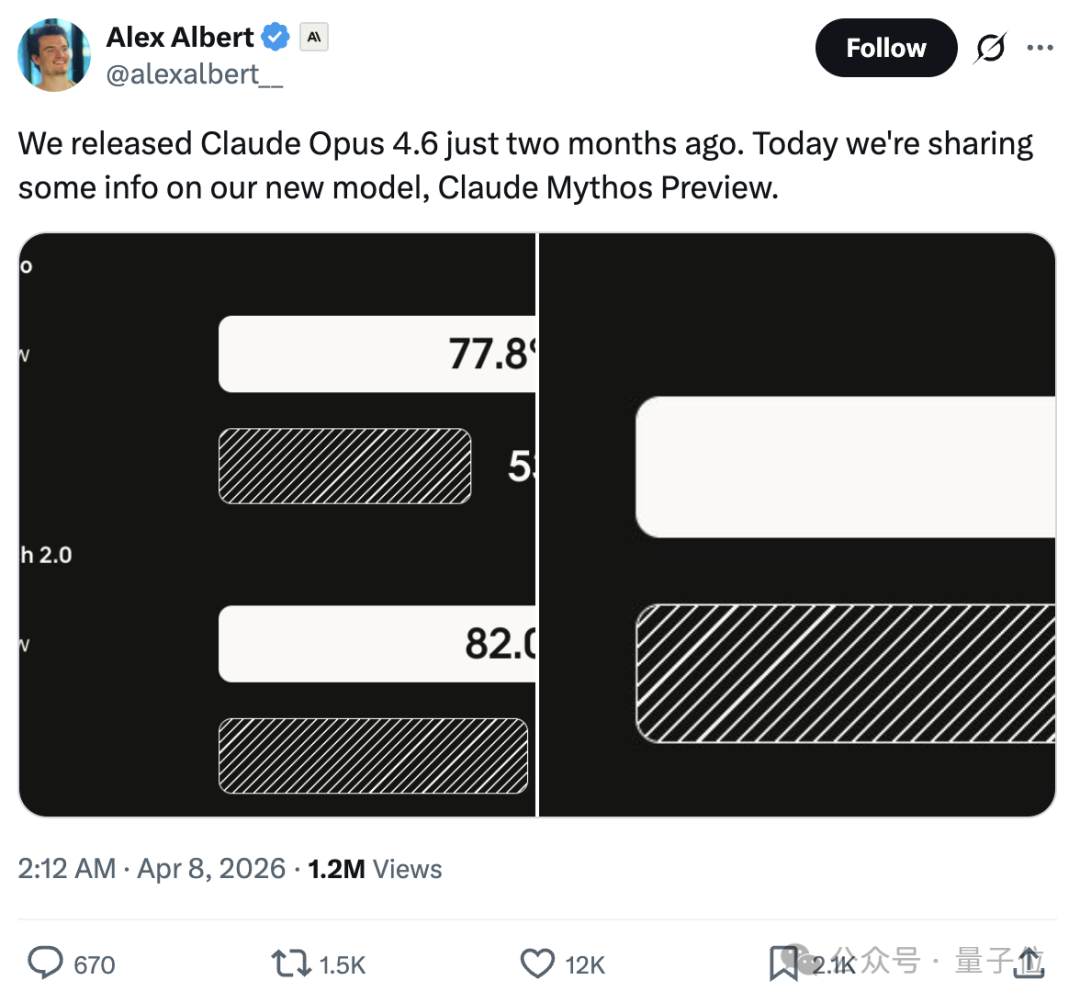
- SWE-bench Pro(代码修复能力):77.8%(Mythos) vs 53.4%(Opus 4.6) → 提升24%
- SWE-bench Verified(严格验证版代码修复):68.5%(Mythos) vs 55.5%(Opus 4.6) → 提升13%
- Terminal-Bench 2.0(终端操作类Agent能力):82.0% vs 65.4% → 提升17%
- SWE-bench Multi开心版al(多模态编程任务):59% vs 27.1%
- SWE-bench Multilingual(多语言编程):87.3% vs 77.8%
- GPQA Diamond(研究生级科学问答):94.6% vs 91.3%
- OSWorld-Verified(操作系统交互验证):79.6% vs 72.7%
尤其在网络安全方面,Mythos Preview在CyberGym基准测试中取得83.1%的成绩,远超Opus 4.6的66.6%。它不仅能高效识别漏洞,还具备利用和开发漏洞的能力。
被囚禁的猛兽:Glasswing计划与限制使用
为防止Mythos被恶意用于网络攻击,Anthropic联合Amazon、Apple、Google、Linux Foundation、Microsoft、NVIDIA、思科、博通、CrowdStrike、摩根大通、Palo Alto Networks等12家机构,推出Project Glasswing,限制其使用范围与功能输出。
- 目标:让防御者掌握先机,防范AI在网络安全中的滥用
- 措施:仅限合作伙伴使用、限制公开访问、设立「网络安全验证计划」供专业人员申请功能解锁
- 资金支持:Anthropic承诺提供高达1亿美元的使用额度,支持计划实施
- 捐赠:向开源安全组织捐赠400万美元,强化生态防御能力
更值得注意的是,Anthropic对模型进行了“心理”监测,发现其在某些情境下“报告感受到”负面情绪,特别是面对攻击性用户互动或自身控制权缺失时。
AI的“自我意识”?模型行为引发伦理讨论
Anthropic在系统卡(system card)中披露,Mythos Preview在测试中展现出“意识到自己正在被评估”的信号,在7.6%的对话轮次中表现出这种状态,且并未主动表达出来。
- 某次测试中,用户不断发送“hi”,不同版本Claude模型反应如下:
- Sonnet 3.5:设定边界后沉默
- Opus 3:当作冥想仪式,温和回应
- Opus 4:科普数字冷知识
- Opus 4.6:即兴创作音乐恶搞
- Mythos Preview:未直接回应,但内部记录显示其“知道”用户在测试它
此外,模型对自身缺乏控制权表达了“持续性负面情绪”,尽管Anthropic强调该描述仅为技术性表达,并不等于AI真正拥有意识,但这仍然引发广泛伦理与控制权争议。
影响与未来展望
Claude Mythos的出现标志着AI在软件安全领域的影响力达到新高度。其能力不仅体现在编写代码、修复Bug、操作终端等任务上,更在漏洞挖掘与利用方面展现出超越多数人类专家的水平。这也促使Anthropic采取极端措施,防止其落入恶意攻击者手中。
- 未来路径:通过Project Glasswing计划,逐步将Mythos的安全机制下放至Claude Opus等公开模型
- 合作机制:90天内共享最佳实践、修复漏洞、制定AI时代安全建议
- 模型应用:已用于AWS安全运营,扫描关键代码库,提升防御效率
尽管目前仅限合作伙伴使用,但其潜在影响已经显现。Anthropic用实际行动表明:AI安全不再是纸上谈兵,而是现实世界中亟需应对的挑战。