京东开源图像模型 JoyAI-Image-Edit,从平面修图升级为三维空间重塑

背景与技术痛点
在AI图像编辑领域,长期以来面临一个核心问题:AI更像是在二维平面上“P图”,而无法理解图像背后的三维空间结构。传统模型在移动物体、更换视角或调整物体前后关系时,常常出现变形、透视错误、遮挡混乱等问题,严重影响编辑效果的真实性和可控性。
这种限制源于现有AI模型主要关注图像的像素层面生成,缺乏对空间关系的深层认知。因此,如何赋予AI真正的“空间智能”,成为提升图像编辑能力的关键所在。
JoyAI-Image-Edit 的技术突破
京东探索研究院推出的 JoyAI-Image-Edit 图像模型,首次将空间认知能力深度融入图像生成与编辑的底层架构。这一技术突破使AI不仅能生成逼真的图像外观,还能精准理解图像背后的三维空间结构。
该模型的主要创新包括:
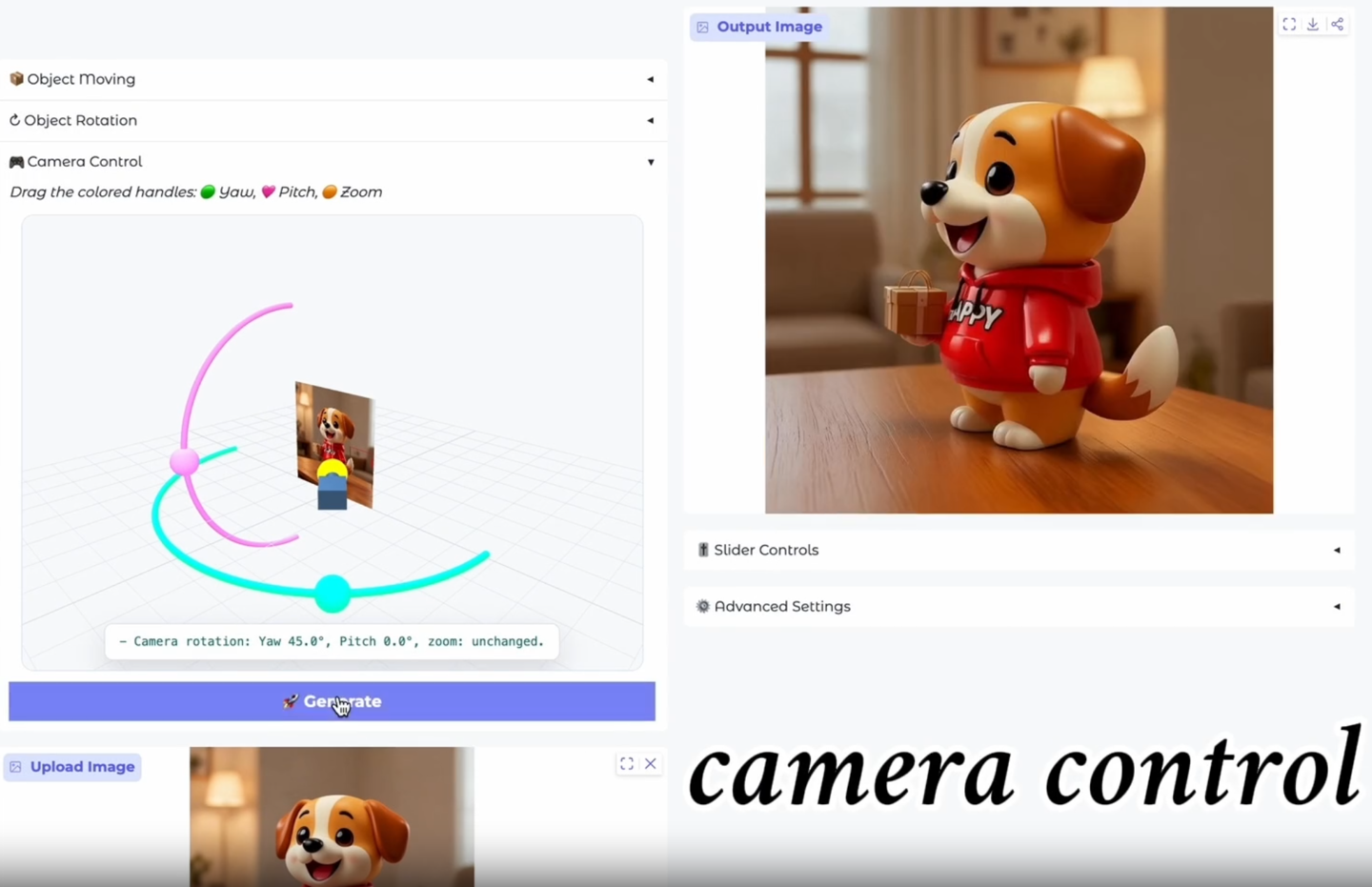
- 构建了完整的空间智能体系
- 强化了图像主体与场景结构的稳定保持能力
- 在编辑过程中遵循真实世界的几何规律
通过这些改进,JoyAI-Image-Edit 实现了从平面修图向三维空间重塑的技术跨越,解决了传统AI图像编辑中常见的遮挡和光影问题。
核心空间编辑能力
JoyAI-Image-Edit 拥有三项核心空间编辑能力,显著提升图像编辑的灵活性和真实性:
- 视角变换:通过自然语言指定相机角度,即可生成符合三维空间逻辑的新视角图像
- 空间漫游:可连续移动视角,生成连贯的多视角画面,模拟真实空间移动效果
- 物体空间关系操控:精准调整物体之间的空间关系,保持遮挡与透视的一致性
此外,该模型还兼容15类通用图像编辑功能,涵盖物体替换、删除、风格迁移及长文本渲染等操作,实现了三维能力与传统编辑功能的深度融合。
应用前景与产业影响
JoyAI-Image-Edit 的开源为多个领域带来了变革性的影响:
- 电商内容生产:可高效生成多视角商品展示图像,提升商品建模与视觉呈现质量
- 创意设计:设计师能够更自由地操控图像空间结构,提升创意表达的维度
- 3D模型重建:从2D图像出发,实现更精确的三维场景重建
- 具身智能视觉感知:为机器人提供理解现实世界空间结构的关键能力,助力智能体视觉感知发展
在当前AI与产业深度融合的大趋势下,JoyAI-Image-Edit 的发布不仅填补了AI图像编辑的技术空白,还为机器人、虚拟现实、智能设计等前沿领域提供了强有力的底层支持。
开源战略与京东AI布局
JoyAI-Image-Edit 的开源是京东AI战略的重要一步。近期,京东不仅开源了该图像模型,还在持续推进基础大模型的开放,并计划打造全球最大的具身数据采集中心。
这一系列举措表明,京东正在从底层模型到产业应用的全链条上发力,推动AI技术与零售、物流、制造等业务场景深度融合,进一步巩固其在智能视觉与空间计算领域的领先地位。