卡帕西没做完的,开源社区48小时搞定了!完全体知识库,token省70倍

近年来,随着AI大模型在数据处理和语义理解方面的飞速发展,构建高效、低成本的知识管理系统成为开发者和研究人员的共同目标。在这一背景下,Graphify 作为一个零配置、全模态、本地运行的知识图谱工具迅速走红。该项目在GitHub开源后仅48小时内就获得了超过2,000颗Star,被视为对Andrej Karpathy提出的个人知识库理念的“完全体”进化版本。
背景:卡帕西的知识库理念引发关注
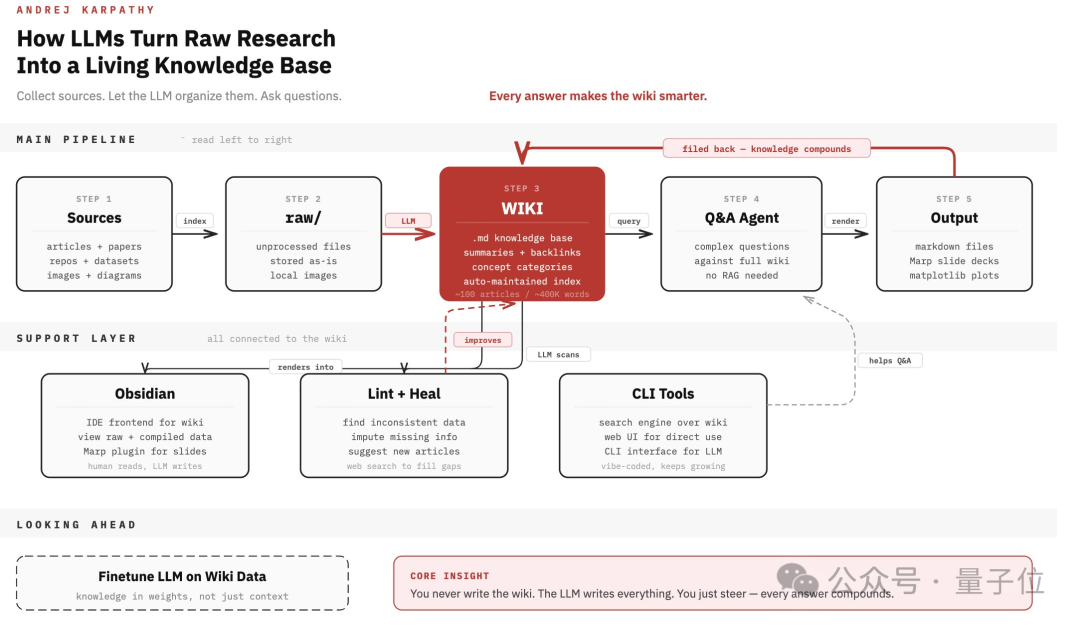
Andrej Karpathy,前特斯拉AI总监、知名AI教育者,曾在社交媒体上分享了自己构建个人知识库的方法。他提出了一种“raw笔记法”,通过将原始笔记以结构化的方式存储,实现知识的高效检索与管理。然而,这种方法虽然概念新颖,但缺乏自动化的图谱构建能力和对多模态数据的支持。
Graphify 的出现填补了这一空白。开源社区迅速响应,仅在48小时内就推出了一套完整的解决方案,将卡帕西的原始想法提升到新的高度。
Graphify 的核心技术亮点
Graphify 的核心创新在于其自动构建知识图谱的能力,结合了高效的本地处理与智能语义提取:
-
零配置、全模态支持
用户无需进行复杂设置,即可处理多种格式内容,包括代码、Markdown、PDF、图像(如白板照片、流程图等)。 -
本地AST解析
对代码文件使用tree-sitter库进行本地抽象语法树(AST)解析,直接提取代码结构信息,避免了云端处理带来的隐私与效率问题。
-
Claude Vision助力视觉语义提取
针对非文本内容,Graphify集成了Claude Vision模型,对图像中的文字与结构进行识别和关系建模,实现视觉信息的图谱化。 -
双阶段语义提取流程
Graphify采用两阶段方法:首先进行本地AST解析,然后通过并行LLM子代理完成语义提取,从而显著提升效率并减少token消耗。
token消耗节省高达71.5倍
Graphify 最引人注目的性能优势之一是其极大的token节省。据项目介绍,其双阶段流程能够在语义提取过程中实现71.5倍的token消耗优化。这意味着:
- 用户可以以更低的成本使用大型语言模型;
- 本地处理减少对云端API的依赖;
- 更适合在资源受限环境下部署,如个人笔记本或小型服务器。
这种节省来源于对嵌入式模型和向量数据库的完全舍弃。Graphify 依靠Leiden社区发现算法,基于图的拓扑结构进行聚类,而不是传统意义上的向量相似度匹配。
无需向量数据库,开箱即用
传统知识管理系统通常依赖向量数据库(如FAISS、Pinecone等)来实现高效检索。但Graphify打破了这一惯例,实现了:
- 不需要嵌入模型(embeddings);
- 不需要向量数据库部署;
- 不依赖外部服务或复杂配置。
这一设计不仅降低了部署门槛,也提升了系统的可移植性和隐私安全性。用户只需将Graphify部署在本地环境中,即可实现从知识输入到图谱构建的全流程自动化。
社区反响热烈,作者背景引人注目
Graphify的火爆出圈不仅体现在其技术先进性,更在于其快速获得开发者社区认可。GitHub开源后短短两天内,项目Stars数迅速突破2,000,成为知识管理领域的黑马项目。
该项目由伦敦Valent公司AI研究员Safi Shamsi主导开发。他此前在AI社区中已有一定影响力,此次Graphify的推出再次展现了其在AI工程与知识系统设计方面的实力。
未来影响与展望
Graphify 的出现为知识管理领域带来了新的范式转变。它不仅提升了处理效率,还降低了技术门槛,使更多开发者和研究人员能够轻松构建高质量的知识图谱系统。
随着开源社区的持续贡献,Graphify 有望成为新一代知识库的标配工具。其设计思路也可能影响其他AI应用,推动更多轻量、高效、本地化的模型部署方案出现。
对于企业和个人用户而言,Graphify 提供了一个高效、省成本、安全可控的知识管理系统参考模型。未来,类似的系统或将成为AI助手、研究协作、数据管理等场景的核心支撑。