面壁智能放大招!开源全尺寸BitCPM-CANN:国产算力首次跑通1.58-bit训练,推理显存省5/6

国产算力首次端到端跑通1.58-bit训练,昇腾生态迎来关键突破
5月25日,面壁智能、清华大学与OpenBMB开源社区宣布正式开源BitCPM-CANN大模型系列。这是中国首个完全基于华为昇腾国产算力平台实现从训练到推理全流程端到端的三值(1.58-bit)大模型,标志着国产AI芯片在超低比特训练技术上实现零的突破。此前,该模型于5月23日在华为鲲鹏昇腾开发者大会(KADC 2026)上完成首次亮相,立刻引发业界关注。
BitCPM-CANN系列覆盖0.5B、1.8B、4B、8B四个尺寸,所有权重均被限制为-1、0、1三个离散值。面壁智能团队表示,通过自研的CANN适配优化方案,成功在昇腾计算平台上完成了原本依赖英伟达CUDA生态的三值训练流程,为国产算力全栈自主可控开辟了全新路径。
三值权重“省”出6倍显存:1.58-bit技术如何改写推理成本
与传统BF16精度模型相比,BitCPM-CANN的1.58-bit技术核心优势在于权重量化策略:每个参数仅占用1.58比特(约2比特),而非BF16的16比特。这意味着,在同等物理显存限制下,模型可容纳的参数量提升约6倍。具体而言,一块原本只能运行8B级别BF16模型的显卡,可以近乎完整加载48B参数的1.58-bit模型;而对于端侧场景,原本需要6GB显存的8B模型推理,现在仅需1GB左右。
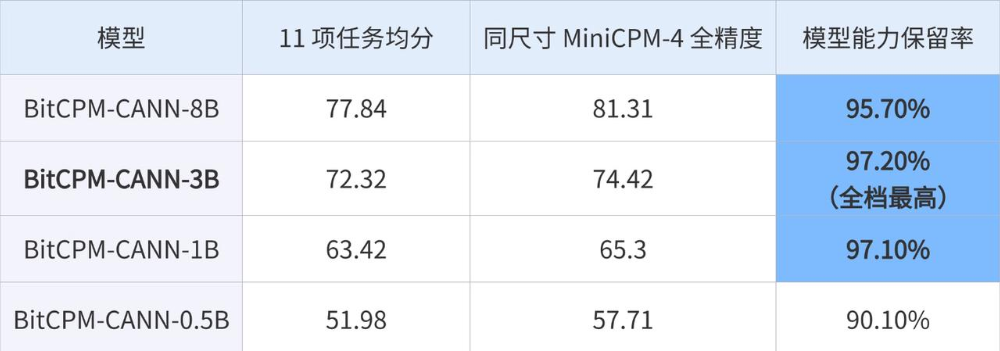
这一显存节省直接转化为硬件门槛降低:BitCPM-CANN的0.5B和1.8B版本甚至可以在手机端流畅运行,无需云端依赖。面壁智能强调,三值化不仅不会显著降低模型能力,反而由于极低比特带来的稀疏化结构,在部分任务上展现出更好的泛化性与推理效率。
全尺寸开源:从端侧到云侧,零门槛复现国产AI创新
BitCPM-CANN系列已在GitHub和魔搭社区(ModelScope)同步开源,包含模型权重、训练代码、推理脚本以及直接在昇腾NPU上运行的部署方案。面壁智能联合OpenBMB遵循Apache 2.0协议开放全部技术细节,开发者可在国产服务器或昇腾边缘设备上自行复现训练与微调。
开源策略覆盖所有尺寸,最低0.5B适合智能家居、可穿戴设备等极致轻量场景;8B版本则可在服务器上以极低显存消耗提供接近BF16精度的对话能力。面壁智能还提供了与业界主流框架(如Transformers、vLLM)的适配指南,降低迁移成本。
国产算力闭环:BitCPM-CANN如何打通训练-推理-部署全链路
BitCPM-CANN的发布不只是模型本身,更是一套完整的国产算力解决方案。面壁智能团队针对昇腾CANN算子库进行了深度三值化改造,实现了原生训练并完成推理引擎适配,使该模型在昇腾芯片上的推理速度与显存效率均达到业界领先水平。这一技术路径填补了国产AI在超低比特训练领域的空白,也为未来更大规模的三值模型(如13B、72B)在国产算力上的落地验证了可行性。
从训练到推理,从开源到端侧部署,BitCPM-CANN系列标志着国产AI在“用更少算力做更多事”的方向上迈出了实质性一步。面壁智能表示,后续将持续优化三值模型的训练收敛效率,并探索在非昇腾国产芯片上的兼容性,进一步拓宽国产算力生态的边界。