Netflix也发视频模型了:不只是“擦除”,而是“重写”物理世界

背景:视频编辑需要“更智能”的物理推理
视频物体移除是视频编辑中的基础任务。传统方法虽然能有效补全背景或消除阴影,但在面对涉及物理交互的场景时却频频失败。例如移除推动物体的手,后续物体的运动轨迹却未改变;或者移除支撑结构后,被支撑物仍然保持静止,这种逻辑矛盾影响了视频的真实感。
Netflix及其合作团队意识到,这类编辑任务实际上需要AI具备“因果推理”能力:不仅要删除目标,还要合理预测删除后整个场景的物理变化。这种能力在当前视频编辑工具中是普遍缺失的。
VOID框架:不只是移除,而是重构物理世界
Netflix推出的VOID(Video Object and Interaction Deletion)框架,首次在视频编辑中实现了对物理因果的建模。该框架基于CogVideoX构建,并结合了Generative Omnimatte的层级物体解耦能力。
核心创新包括:
- 反事实数据集构建:借助物理仿真引擎生成训练数据,模拟物体不存在时的场景演化。
- 交互感知的四值掩码(quadmask):提供更精确的条件输入,标记目标物体及其可能影响的区域。
- VLM引导的推理机制:利用视觉-语言模型自动识别被移除物体影响的范围,辅助模型做出更合理的物理推演。
技术流程:两阶段优化,提升物理一致性
VOID的推理流程分为两个阶段,以确保生成视频在物理上更加合理。
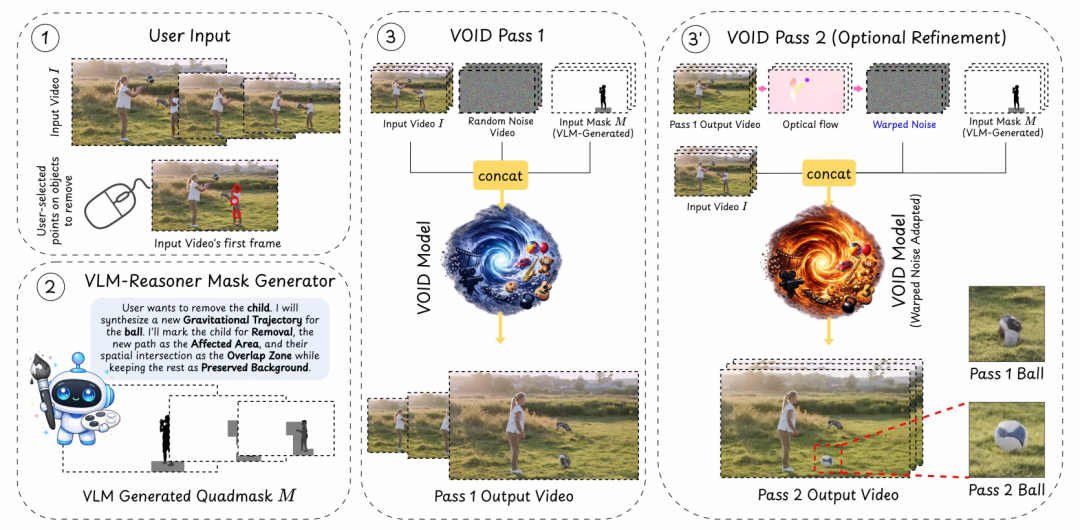
第一阶段:反事实轨迹合成
模型根据输入视频和四值掩码生成初步的反事实预测。这一阶段可以捕捉到基本的物理变化方向,例如在移除支撑物后,物体开始自由落体。但由于扩散模型在处理复杂动态时容易出现物体变形等问题,需要进一步优化。
第二阶段:光流引导的噪声稳定
在第一阶段的基础上,VOID提取光流场,生成时序相关的扭曲噪声作为第二阶段的输入。这一过程显著提升了视频在时间轴上的一致性与物体运动的合理性。VLM会根据场景动态决定是否启用这一阶段。
性能评估:多项指标领先,展现强大泛化能力
真实视频评估
- 人类偏好测试:25名参与者评估5个场景,从7个模型中选择最佳结果。VOID以64.8%的胜率位居第一,Runway仅18.4%。
- VLM自动评分:Gemini 3 Pro、GPT-5.2和Qwen 3.5-32B评分中,VOID在交互物理、时序一致性等维度得分最高。
- 定性案例分析:在移除支撑手后,VOID成功模拟自由落体;移除狗后,棍子自然掉落;移除搅拌机按钮上的手后,搅拌机不再启动等。
合成数据集评估
在多个视频质量评估指标(如FVD)中,VOID表现优异。LPIPS等对局部位移敏感的指标中,VOID略逊一筹,但这是因为其物理模拟的动态变化在数值指标上可能“偏离”原视频。
行业影响:重新定义AI视频编辑方向
VOID的提出,不仅提升了视频移除的物理真实性,更开辟了AI视频编辑中“因果建模”的新方向。它不再依赖对背景的简单补全,而是基于对场景中物体互动的理解,进行“重写”式编辑。
- 影视制作:可实现更自然的后期编辑,如删除道具或特效后仍保持场景连贯。
- 内容审核:在去除违规或敏感内容时,能保持画面逻辑一致性。
- AI创作工具:为AI视频生成提供“编辑-重构”闭环,推动生成式视频工具的实用性提升。
未来展望:物理推理能力将成AI视频编辑标配
研究团队指出,随着视频生成模型与视觉-语言模型的持续进化,VOID的性能有望进一步提升。更重要的是,这项工作揭示了AI视频编辑的一个全新方向:如何将世界建模能力与生成模型结合,实现更深层次的场景理解。
这不仅仅是技术上的突破,更可能引发AI视频工具的范式转变:从“被动修改”走向“主动推理”,为视频创作、编辑、修复带来前所未有的可能性。