牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离

从“事后补救”到“主动断舍离”:AI记忆管理的范式革命
长期以来,大语言模型处理长文本时面临一个核心瓶颈:自注意力机制中的键值(KV)缓存会随序列长度线性膨胀,占据海量显存。现有方案多为“事后压缩”——模型训练完成后,再用各种算法对已产生的缓存进行精简,仿佛等垃圾堆满房间才开始打扫。
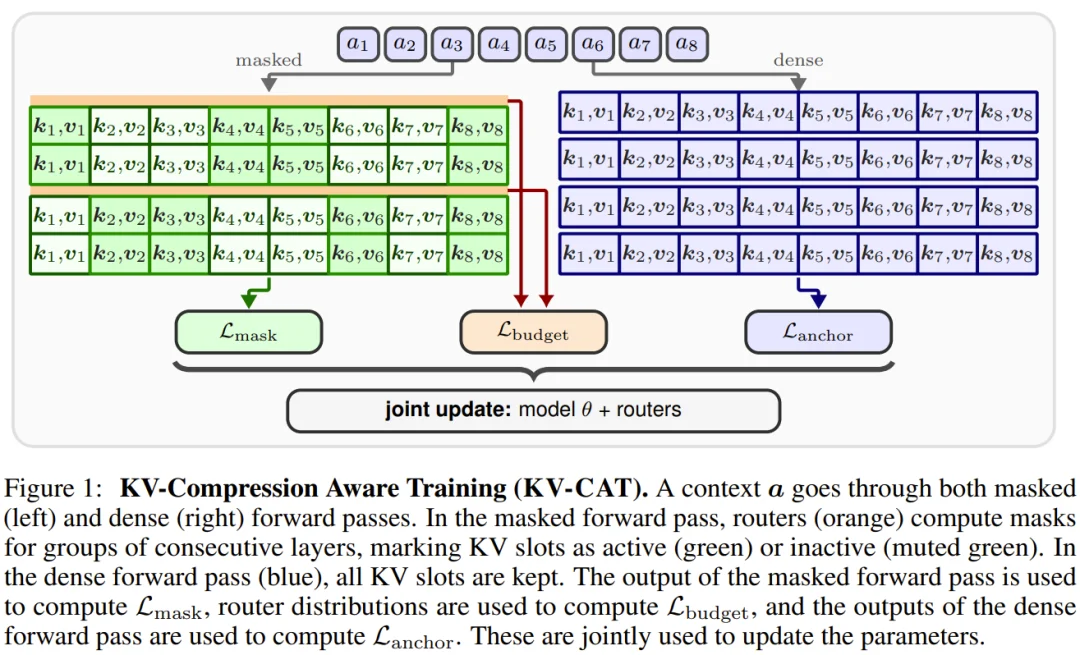
来自牛津大学、以色列理工学院、AITHYRA 和英伟达的联合研究团队提出了截然不同的思路:在训练阶段就让模型学会对记忆进行“断舍离”。通过引入结构化压缩机制,模型能够自主判断哪些历史信息值得保留、哪些可以丢弃,从而从根本上减少不必要的缓存生成。这一范式将压缩从“被动修剪”升级为“主动规划”,直接改变了模型对长上下文的管理逻辑。
提速35倍,性能不降:新范式的硬核指标
该技术的实际效果令人瞩目:
- 128K超长文本处理:速度比全注意力模型快2.7倍
- 2M超长上下文处理:速度提升达35倍
最关键的是,性能丝毫未打折。传统压缩方法往往牺牲精度换取速度,但训练时引导模型“断舍离”能让其自然适应稀疏记忆模式,避免了事后压缩带来的信息损失。这意味着在极端长上下文场景(如多轮对话、大型文档推理)下,用户无需再在推理成本与模型表现之间痛苦权衡。
结构化压缩:让模型自己学会丢弃无用记忆
团队实现了两种压缩变体,其中“结构化”实现是核心突破点。它允许模型在注意力计算过程中,对KV缓存进行分层、分块的动态管理:
- 模型在训练中被赋予一个“压缩感知”loss,用以学习每个时间步的记忆重要性
- 对不重要的缓存项,模型主动将其“融合”或“丢弃”,而非全部保留
- 压缩后的缓存保持结构化格式,兼容现有GPU内核,无需额外反序列化
这种设计让模型在推理时不再盲目复制全量缓存,而是直接输出精简后的KV序列,实现了“一次性生成、自带压缩”。
与DeepSeek条件记忆的差异:一条不同的技术路线
近期大火的DeepSeek条件记忆模块同样致力于控制注意力开销,但两者路径截然不同:
| 方面 | 本项技术 | DeepSeek条件记忆 |
|---|---|---|
| 核心思路 | 训练时让模型主动压缩KV | 推理时根据条件动态选择记忆范围 |
| 实现方式 | 结构化压缩加自适应丢弃 | 基于门控机制的记忆调度 |
| 适用场景 | 超长上下文(百万token级) | 中等长度上下文(数千token) |
| 速度优势 | 2M上下文加速35倍 | 主要降低显存占用,速度提升有限 |
本项技术的“断舍离”范式更激进——直接改变模型对记忆存留的认知,而非仅在运行时做选择。对于需要处理极长文本(如法律文档、基因组数据)的应用,这一创新有望重新定义效率上限。