Perplexity Computer 下月将拆分 AI 任务,隐私和算力各走一边

19 个模型“各司其职”,任务自动拆解
Perplexity Computer 的核心在于不再依赖单一模型完成所有工作。它内置多达19个不同AI模型,能自动将用户指令拆解为多个子任务,并分配不同的子代理(sub-agents)执行。例如,用户要求扫描28万行Python代码并修复错误时,系统会生成多个子代理,分别负责分析、推理和修复。
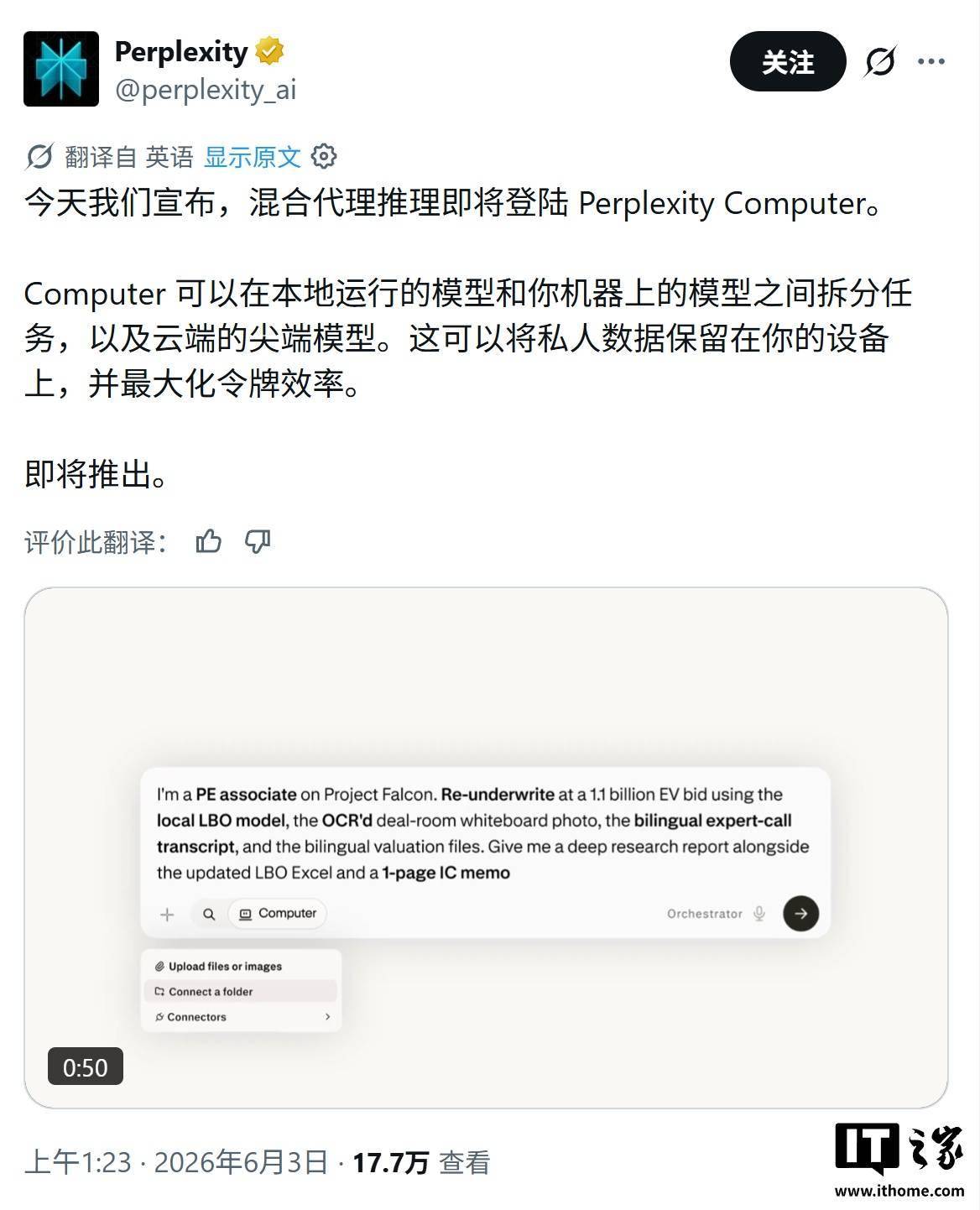
Claude 主推理,Gemini 做研究,算力精准投放
每个模型只做自己最擅长的事:Claude 负责复杂逻辑推理,Gemini 承担深度研究任务,Grok 处理轻量级即时响应,ChatGPT 5.2 则专注于文本生成。这种“各取所长”的调度机制避免了算力浪费,也使得隐私敏感数据(如本地代码库)可以在不离开用户设备的前提下由轻量模型处理,而重度推理任务则交给云端大模型——算力与隐私的“分流”由此成真。
硬件算力底座同步升级:MTIA 芯片性能飙升25倍
算力分离的背后是硬件的强力支撑。Meta 新一代MTIA芯片(从MTIA 300到MTIA 500)将高带宽内存(HBM)带宽提升4.5倍,算力提升高达25倍,大幅强化大语言模型的推理效率。这为Perplexity Computer 在本地端处理轻量模型、云端端运行重型模型提供了可行的算力保障,让“隐私友好型”本地代理与“高性能型”云代理并行走得通。
隐私与算力“分道扬镳”:下月新架构落地
Perplexity Computer 下月即将实施的拆分策略,本质上是将AI任务按照隐私级别和算力需求进行路由:用户敏感数据(如个人文档、代码)由本地轻量子代理处理,非敏感或高算力需求任务(如大规模知识检索、复杂推理)则交由云端昂贵模型执行。这种“各走一边”的设计,既规避了敏感数据上云的风险,又算力无浪费。未来,Perplexity Computer 或将成企业级AI部署的标杆方案。