
Query Fan-Out Optimizer是什么
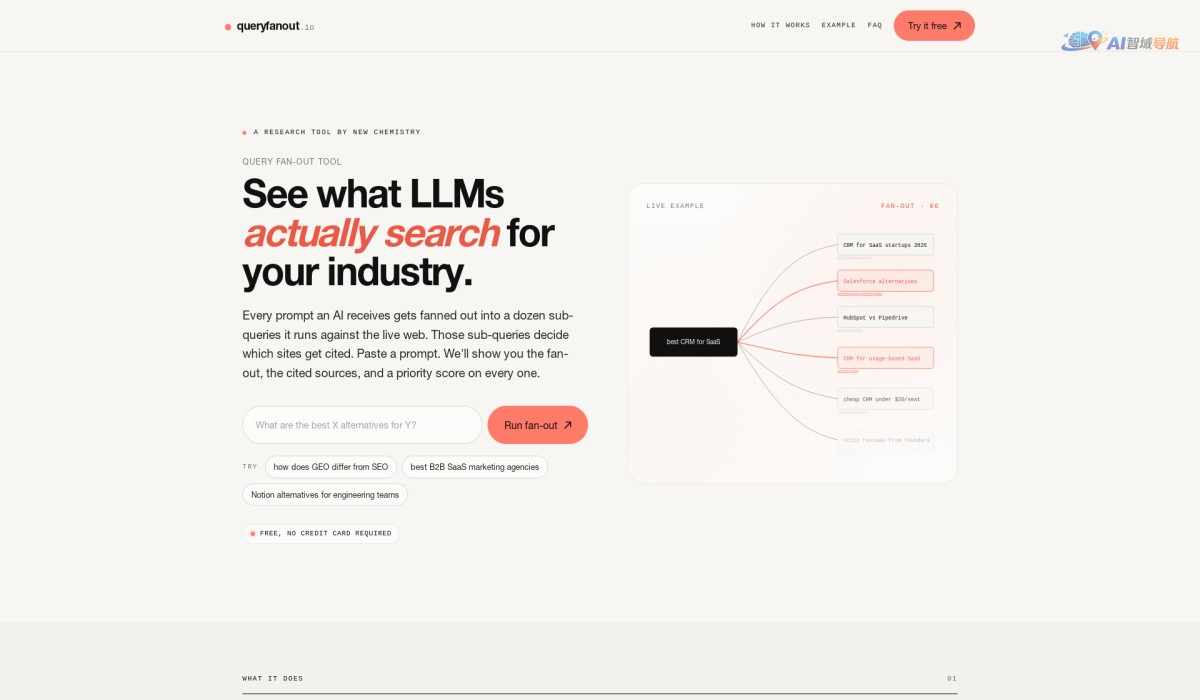
Query Fan-Out Optimizer 是一款专注于解析大语言模型(LLM)内部检索逻辑的分析工具。它通过逆向工程的方式,将 LLM 在生成回答时实际派发的多个隐含子查询(sub‑queries)逐一拆解并可视化,帮助用户理解模型如何从网络来源中筛选、组合并引用信息。该工具尤其适用于需要审计 LLM 信息溯源质量、优化检索增强生成(RAG)管道以及提升引用透明度的场景。
核心优势
- 深度透明化:揭开 LLM “黑箱”中针对网络搜索的扇出行为,展示模型实际上同时搜索了哪些不同角度或关键词的子查询。
- 引用可解释性:将最终引用的来源与具体的隐含子查询一一对应,便于验证引用是否准确、是否存在幻觉。
- 性能优化线索:通过分析子查询的冗余度与命中率,指导开发者精简或重组查询结构,降低检索延迟与成本。
技术原理简述
该工具通过以下步骤工作(使用无序列表):
- 请求拦截:在 LLM 与搜索引擎交互的中间层捕获原始查询请求,识别出模型自动生成的多条独立子查询。
- 语义聚类:利用 NLP 模型对子查询进行聚类,去重并标记主题差异(如事实性查询 vs. 对比性查询)。
- 溯源映射:将每个子查询的搜索结果与最终回答中的引用块进行匹配,生成子查询-引用的关联网。
适用人群
| 角色 | 典型用途 |
|---|---|
| LLM 应用开发者 | 诊断 RAG 管道的查询策略是否合理,减少无效的扇出请求。 |
| 内容质量审核员 | 验证 AI 生成的引用是否真正源自合理的子查询,而非捏造。 |
| 研究机构 | 分析不同 LLM 在搜索策略上的系统差异与偏见。 |
典型使用场景
- 审计复杂问答:当 LLM 回答涉及多个事实交叉验证的问题时,通过工具展开隐含子查询,检验每个子查询对应的证据链是否完整。
- 优化搜索成本:识别出重复或低效的子查询,合并或删除后减少 API 调用次数,节省费用。
- 提升合规性:在医疗、法律等需要严格引用的领域,确保每个声明的支撑来源都对应一个真实的隐含搜索动作。