让AI自我构建的RSI火了,Google泼冷水,DeepSeek们摸到了边

RSI爆火:AI界新晋“顶流”与两大路线之争
随着“递归式自我改进”(Recursive Self-Improvement, RSI)概念的走红,AI行业再次陷入狂热。两家初创公司甚至直接将“RSI”写进公司名称,众多实验室也将其列为关键技术路线。简单来说,RSI就是让AI自己训练自己,人类在其中不再是必要条件。这股浪潮中,最引人注目的两个实践是:
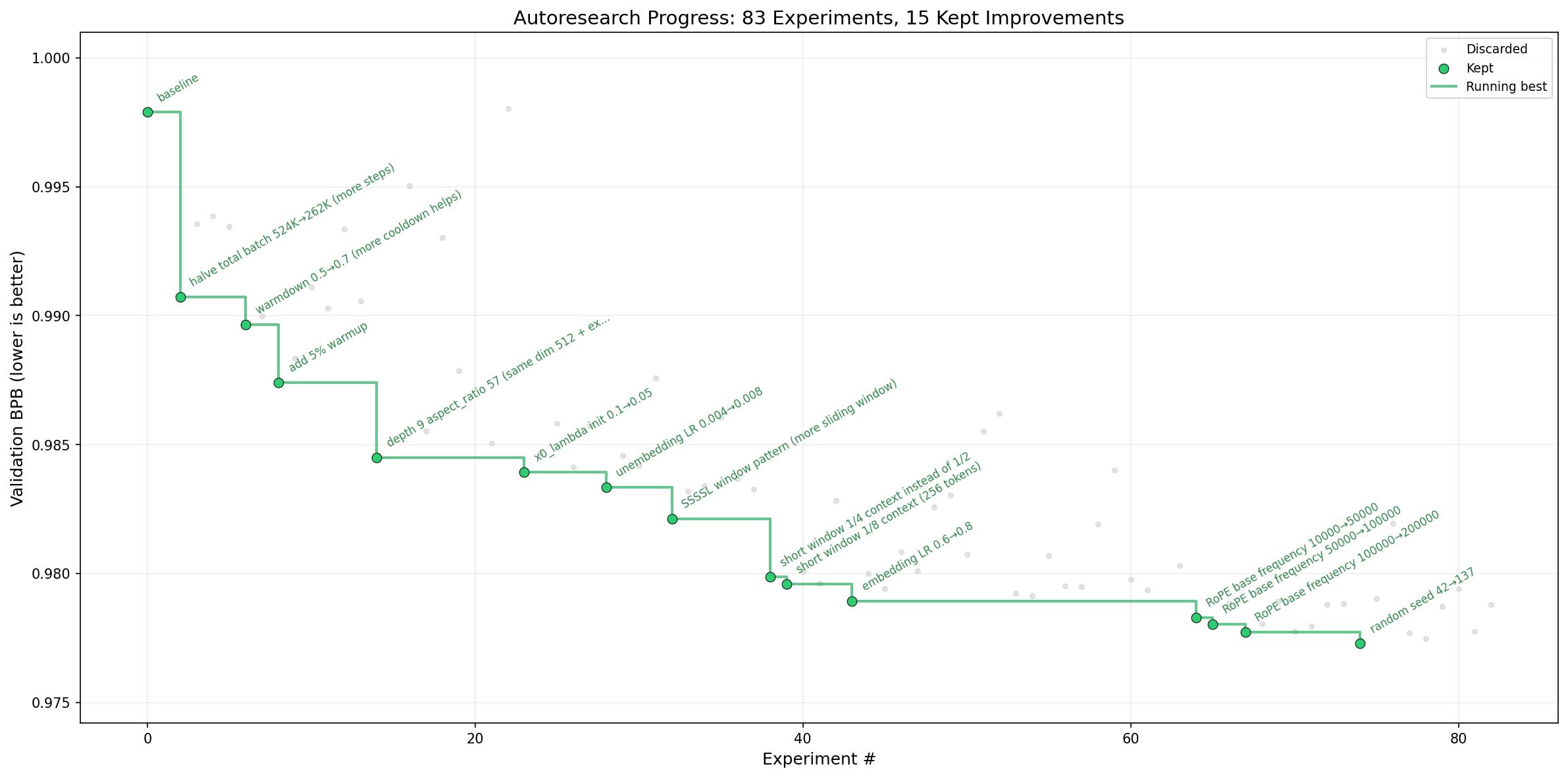
- 安德烈·卡帕西(Andrej Karpathy)的Auto-Research项目:这位前特斯拉、OpenAI大牛,正试图用智能体集群来训练语言模型,让模型自己完成研究任务并自我改进。他不仅公开了GitHub代码,还定期更新进展,尽管目前只在GPT-2级别的小模型上迭代,但他加入Anthropic预训练团队后,其方法论与Claude模型的结合被寄予厚望。
- Adaption公司的AutoScientist工具:与卡帕西的“底层逐块验证”路线不同,Adaption的目标更为宏大,他们想直接打造一个针对全尺寸前沿模型的自动化训练闭环,商业化落地意图更为强烈。
这两条路线——一条从底层稳扎稳打、开源攒势,另一条直奔商业化训练场景,究竟谁能率先跑通,将对行业产生截然不同的影响。
Google CEO泼冷水:“我们还没到那一步”
与业界的狂热形成鲜明对比,Google CEO桑达尔·皮查伊在一档播客中直言,虽然大家都在进步,但RSI所描述的那种“下一个量级的加速”尚未到来。不过,他使用的“连续体”一词,却暗藏了一个令人细思极恐的现实:Anthropic一位Claude Code开发者坦言,团队近100%的代码已由Claude Code自己编写。更有一份内部调查显示,在18名工程师中,有5人认为改进后的Mythos版本已能替代一名中级程序员。
然而,这恰恰暴露了RSI的根基短板:AI难以自我驱动。Claude的弱点恰恰是处理模糊任务、理解组织优先级、把握品味和验证方向等人类擅长的领域。
爬坡模型与加速推演:RSI的三个里程碑
为了更清晰地理解RSI的发展阶段,METR研究员Ajeya Cotra提出了一个实用的分析框架,将其分为三个等级:
- 第一级:足够(Adequacy):系统在完全移除人类后,依然能自主做研究,即便效率不如人类。
- 第二级:对等(Parity):AI独立完成的研究质量,与人类独立完成的研究水平相当。
- 第三级:超越(Supremacy):AI独立系统的表现,超越了任何人类与AI协作的系统。
这个框架类似于自动驾驶的L2至L5分级。Ajeya Cotra判断,我们离第一级已经很近,而一旦达到第二级,后续的加速将“断崖式”上升,AI将成为一个无需休息、可以不间断试错的研究团队,人类深度工作的时间瓶颈将不复存在。
国内玩家“闷声发财”:DeepSeek与百度文心已摸到边
与海外高调喊口号不同,国内厂商虽然很少公开谈论RSI,但在“让AI自我改进”的实践上,已经悄悄摸到了边界:
- DeepSeek的“巧劲”:他们以惊人的成本效率,在推理任务上与国际巨头正面竞争。其秘诀在于对MoE架构、激活参数和训练策略的极致工程优化,这恰好契合了RSI的核心逻辑——用更聪明的方法替代蛮力堆算力。
- 百度文心的“日常实践”:强化学习驱动模型自我优化已是他们的常规操作。虽然没有RSI之名,但模型通过自反馈循环进行改进的路径,与RSI的某些环节如出一辙。
不过,差距依然客观存在。在人才密度上,国内厂商相较OpenAI和Anthropic仍处于跟随状态。但历史经验表明,一旦可复现的路径走通(如Karpathy开源的代码),国内厂商的成本控制能力和应用场景密度将是难以估量的变量。
现实的冷水:数据塌方与理想条件的缺失
在描绘RSI美好前景的同时,也必须正视几个棘手的现实问题:
- 数据塌方:AI自己生成的数据中,混杂着幻觉、偏见和质量退化。如果用这些“二手货”来训练下一代AI,系统会像不断复印的复印件一样,在几代循环后迅速崩塌。
- 理想条件不存:RSI的运转需要两个前提——无限算力和全球开放协作的研究生态。而现实是,训练前沿模型成本已达十亿量级,芯片产能、能源和优质数据都在减少。出口管制和技术脱钩更是将AI研究割裂成孤岛,基础条件尚不成熟。
整个行业的发展正驱动人类一步步退出决策链条:从“参数崇拜”到RLHF,再到如今RSI描绘的“机器自己跑完研发”故事。这种退出或许并非坏事,但它不可逆转。如同GPS使用久了会弱化认路能力一样,一旦某个环节被自动化接管,人类的经验和判断力也将随之退化。