让大模型多模态检索全面超越SOTA!ReCALL框架化解生成式与判别式的范式冲突|CVPR’26

多模态大模型(MLLM)在视觉理解和语言推理方面表现出色,被视为图像检索任务的理想工具。然而,将其直接适配为判别式检索器时,常因强制压缩高维推理至单一向量,导致细粒度理解能力显著退化。这一范式冲突成为制约大模型在图像检索领域落地的关键瓶颈。
范式冲突:从“智能模型”到“盲检索器”的能力退化
- 生成式模型通常依赖链式推理(Step-wise reasoning)来理解图像中的复杂语义关系。
- 现有检索适配方法多采用判别式范式,通过将大模型输出压缩为固定长度的向量进行相似度计算。
- 实验显示,在原生模型能100%识别的子集上,传统微调后模型在CIRR和FashionIQ数据集的R@1分别跌至62.33%和55.80%。
这一“智能倒退”现象表明,直接微调不仅未能有效迁移生成式模型的推理能力,反而在检索任务中丢失了其原本的细粒度识别优势。
ReCALL四阶段校准框架详解
作者团队提出ReCALL框架,分为四个阶段:
Stage 1:基础检索适配(Baseline Adaptation)
- 使用InfoNCE损失函数对原生大模型进行微调,构建基础检索器(Rbase)。
- 此阶段虽赋予模型基本检索能力,但也暴露出细粒度理解退化的问题。
Stage 2:自我诊断(Diagnose)
- 利用基础检索器在训练集上运行,识别其检索失败的样本(Informative Instances)。
- 这些样本通常与正确图像差异极小,代表了模型的认知盲区。
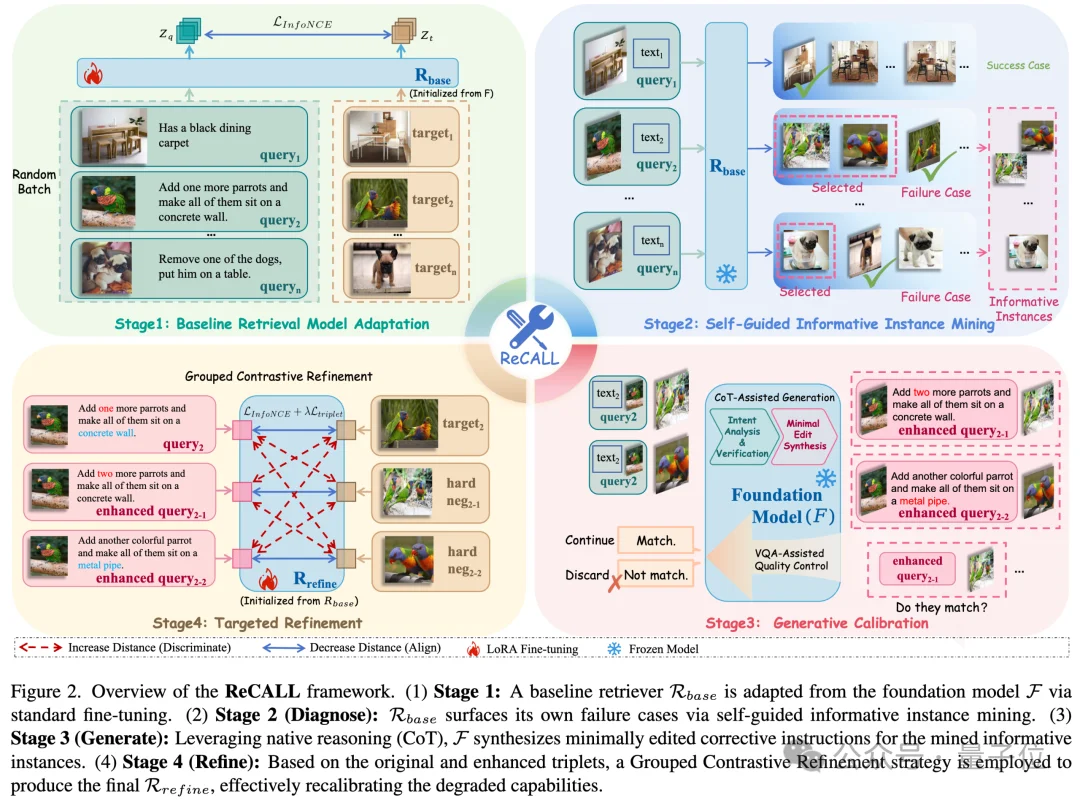
Stage 3:生成校正(Generate)
- 基于模型的推理能力,采用链式思考(CoT)诱导机制生成纠错样本。
- 分为两个核心步骤:
- 意图分解与验证(Intent Decomposition & Verification): 将原始指令拆解为多个“原子意图”,并逐项验证其在错图中的实现情况。
- 最小编辑合成(Minimal Edit Synthesis): 仅修改违背意图的部分,生成新的查询文本,形成“参考图-纠错指令-错图”的三元组。
这一阶段通过最小编辑原则生成高保真的纠错样本,确保新数据与原始分布高度一致,并结合VQA级别的语义一致性过滤,去除幻觉与噪声。
Stage 4:针对性打磨(Refine)
- 引入“分组对比学习”机制(Grouped Contrastive Refinement)。
- 将原查询与纠错查询配对输入模型,引导其识别细微的视觉-语义边界。
- 通过双重优化目标,增强模型对细粒度差异的判别能力。
整个框架实现了从错误识别、意图理解、文本生成到模型优化的闭环流程,有效保留并激发了大模型的原生推理能力。
实测表现:全面刷新CIRR与FashionIQ数据集SOTA
-
CIRR数据集:
- ReCALL实现R@1达55.52%,相较基线模型提升8.38%。
- 在细粒度子集上的R_subset@1高达81.49%。
-
FashionIQ数据集:
- ReCALL平均R@10达到57.04%。
- 在“正视镜头”、“半袖”等细节描述任务中表现优异。
对比实验显示,传统适配模型在面对细微差异时频频出错,而ReCALL校准后的模型能够准确锁定目标图像,展现出强大的细粒度图文对齐能力。
技术启示:生成式与判别式的融合新路径
ReCALL的成功不仅体现在性能提升上,更在于它提供了一种全新的大模型适配范式:
- 从“盲目对齐”到“自我纠正”:不再依赖外部标注数据,而是利用大模型自身推理能力生成纠错样本。
- 保留高维推理,精准建模判别边界:通过链式思考和最小编辑机制,让生成能力服务于判别任务,避免信息损失。
- 闭环式能力校准:诊断问题、生成修正、强化训练,形成可复用的适配方法论。
这种思路为多模态大模型在其他下游任务中的无损适配提供了借鉴,特别是在垂直领域如电商、医疗、自动驾驶等需要高精度视觉语义理解的场景中,ReCALL展现出了广阔的应用前景。
结语与资源链接
ReCALL框架标志着大模型检索适配进入新阶段,不仅提升了多模态检索的性能边界,也为生成式与判别式范式的融合开辟了道路。