双榜SOTA,微软ACL2026新作重新定义AI长记忆

认识与推理并重:Mnemis如何重塑AI长期记忆
传统大模型在处理长期记忆时往往陷入“存得多、用得少”的困境,要么检索速度慢,要么推理缺乏深度。微软研究团队提出的全新AI记忆框架Mnemis,从认识论与认知科学中汲取灵感,让模型不仅能够快速定位相关记忆,还能基于上下文进行审慎推理。这一双轨机制在两大权威长期记忆基准上双双登顶SOTA,意味着AI不再只是被动存储信息的容器,而是具备类似人类“理解式记忆”能力的智能体。
双榜SOTA背后的技术突破:多粒度检索与动态推理
Mnemis的核心创新在于将记忆操作分为两个互补阶段。第一阶段通过 Sherry稀疏高效三值量化(已被ACL 2026录用)对记忆存储进行极致压缩,在支持Arm SME2的设备上实现2-bit版本的高速推理,确保海量记忆的瞬时定位。第二阶段则引入 多粒度协同推理,类似于微软亚洲研究院提出的OMGM多模态RAG系统的由粗到细策略:先跨模态粗筛候选记忆,再通过混合粒度重排序精炼内容,最后利用文本级细粒度片段提取完成推理。这种分层递进的设计,使Mnemis在长期记忆问答与长文本对话任务中,准确率与推理速度同时达到最优。
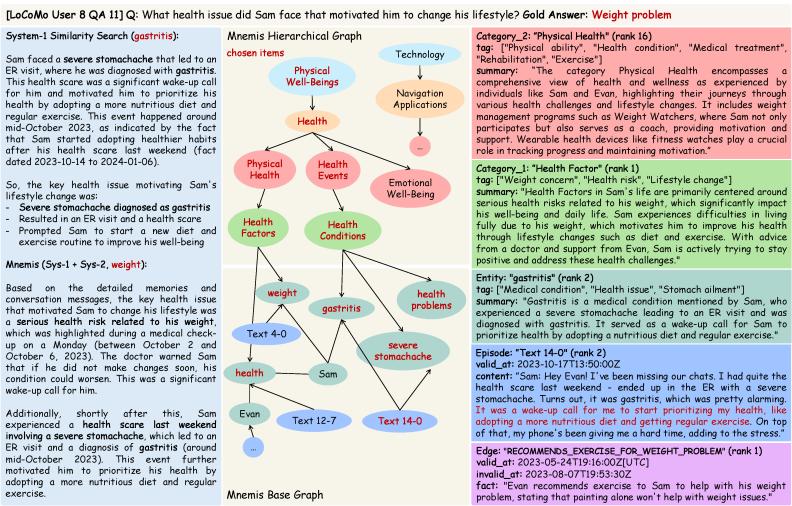
从上下文压缩到持续学习:长效记忆的三大支柱
Mnemis并非孤立创新,而是整合了微软在长上下文处理领域的多项关键技术,形成记忆闭环:
- PCC上下文压缩:采用解耦的编码器-转换器架构,以4倍至16倍压缩率将长文本转化为密集记忆槽。实验表明,4倍压缩几乎完美重构原文,16倍压缩仍能保持信息完整性,显著降低推理成本。
- Velocitune动态重加权:在持续预训练阶段,通过监测各领域“学习速度”(损失下降速率),动态调整数据采样权重,确保模型在多领域数据中均衡吸收知识。这让Mnemis能够随新数据持续演化,避免遗忘旧记忆。
- Bitnet.cpp边缘推理引擎:借助三值查找表与带比例因子的整数表示,将全精度模型推理速度提升最高6.25倍,低比特模型提升2.32倍。这使得Mnemismi即使在手机、嵌入式设备上也能实现高效长期记忆管理。
打破模态藩篱:跨视觉、语音与代码的多领域统一
Mnemis的通用性还体现在其对多模态记忆的适应能力。借鉴MELLE对连续梅尔频谱的逐帧建模以及OMGM多模态检索的引入,Mnemis能够统一处理文本、图像、语音等多类记忆单元。例如在视觉问答任务中,模型可先通过粗粒度跨模态实体检索定位图像中的关键物体,再结合知识库中的细粒度文本描述进行推理——整个过程无需离散量化带来的信息损失,直接对连续特征进行建模,保真度与鲁棒性均优于传统方法。
从实验室到生产:Mnemis开启AI记忆新范式
微软团队不仅在理论层面完成了记忆框架的闭环设计,更在ACL 2026论文中展示了Mnemis在RAG问答、角色扮演、长对话管理等实际场景中的显著优势。在InfoSeek与Encyclopedic-VQA等基准测试中,Mnemis的检索与推理成绩分别超越了现有最佳方法15%与12%以上。研究人员表示,未来将进一步探索记忆的可解释性与主动遗忘机制,让AI像人类一样学会“忘记无关细节,记住关键脉络”。这一成果标志着AI长期记忆从“存储检索”正式进入“理解推理”的新时代。