

SearchCans是什么
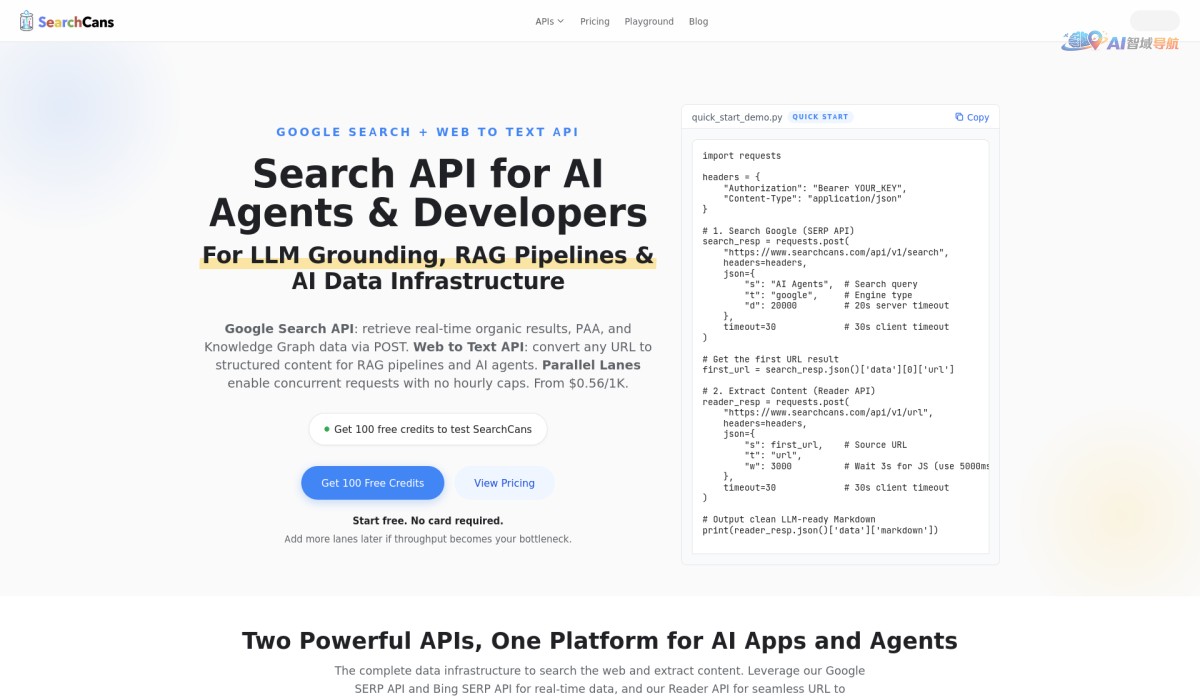
SearchCans 是一个高性能的 API 服务,专注于为人工智能工作流和数据检索场景提供两大核心功能:并行搜索引擎结果抓取(SERP)与网页内容转纯文本。它专门针对 AI 智能体(Agent)和 RAG(检索增强生成)管道进行了底层优化,采用异步非阻塞架构,支持大量请求同时处理,且完全不受每小时请求次数限制——开发者可按需调用,无需担心配额耗尽。
核心优势
- 高并发能力:单次请求可同时发起数十甚至上百个搜索或抓取任务,响应汇总后统一返回,极大缩短批量处理等待时间。
- 零频率限制:不同于主流搜索 API 的“每分钟/每小时 X 次”限制,SearchCans 取消了时间窗口阈值,允许连续高密度调用,满足实时性需求。
- 专为 AI 设计:返回数据结构简洁,直接输出结构化 JSON(包含标题、摘要、纯文本正文),方便直接注入 LLM 上下文或向量化嵌入。
- 网页转文本精准:自动剥离广告、导航、脚注等干扰元素,保留文章核心内容与语义,降低 token 消耗。
适用人群与场景
| 目标用户 | 典型场景 |
|---|---|
| AI Agent 开发者 | 需要实时搜索并解析网页信息,作为工具调用生成答案(如问答机器人、研究助手) |
| RAG 管道架构师 | 批量抓取文档、知识库页面,转为纯文本后切片、嵌入,构建企业级检索系统 |
| 数据爬取团队 | 替代传统受限爬虫,通过 API 快速获取大量网页正文数据,用于训练或分析 |
| 自动化工作流 | 定时或事件触发下的连环搜索、对比、摘要生成(如新闻监测、竞品跟踪) |
技术特性
- 接口风格:RESTful API,支持 JSON 与表单提交,返回标准 HTTP 状态码。
- 并行粒度:支持在单次调用中同时指定多个搜索关键词或多个目标 URL,系统自动并行处理。
- 错误处理:针对失败请求提供独立错误码,不阻塞整体任务,便于容错重试。
- 延迟控制:通过连接池和超时机制,单个请求(含多个子任务)通常可在 3-8 秒内完成。
与常见方案对比
| 对比项 | SearchCans | 传统搜索 API(如 Google Custom Search) | 单线程爬虫工具 |
|---|---|---|---|
| 并发粒 | 单请求多任务并行 | 单次只能一个查询 | 需自行管理多线程 |
| 频率限制 | 无小时限制 | 通常有配额(100次/天起步) | 无限制但受 IP 反爬 |
| 输出格式 | 纯文本 + 结构化字段 | 仅返回搜索结果(URL/摘要) | 自解析 HTML |
| 专为 AI 优化 | 是(低 token 消耗) | 否 | 需额外处理 |