手机上跑MoE?Meta提出MobileMoE,iPhone 16 Pro提速3.8倍

共享专家+细粒度路由:MobileMoE如何让手机跑起MoE?
传统MoE模型因内存和算力门槛高,长期被困在云端。Meta团队提出的MobileMoE专为端侧部署设计,核心思路是细粒度路由与共享专家结合:模型沿用decoder-only Transformer架构,但将密集前馈层替换为MoE层。路由器为每个token选出得分最高的少数专家参与计算,同时引入一个始终参与的共享专家,确保关键知识不被遗漏。最终配置为60个细粒度路由专家、Top-4路由和1个共享专家(E=8、g=8),在效果与训练开销间取得最佳平衡。
四步训练与关键消融:E=8、g=8是最佳平衡点
训练流程分为预训练、中期训练、监督微调、量化感知训练四步。消融实验揭示关键发现:固定内存预算下,当内存高于约0.25GB时,MoE损失开始低于密集模型;增加专家数E可进一步降低损失,但E超过8后边际收益骤降。专家粒度g方面,更细粒度配置整体更优,g=8平衡了效果与训练开销——若从g=8增至g=16,损失改善不足0.01,训练时长却增加约50%。加入共享专家后,相同计算预算下损失进一步下降。
14项评测胜出:MobileMoE以更少参数超越同体量模型
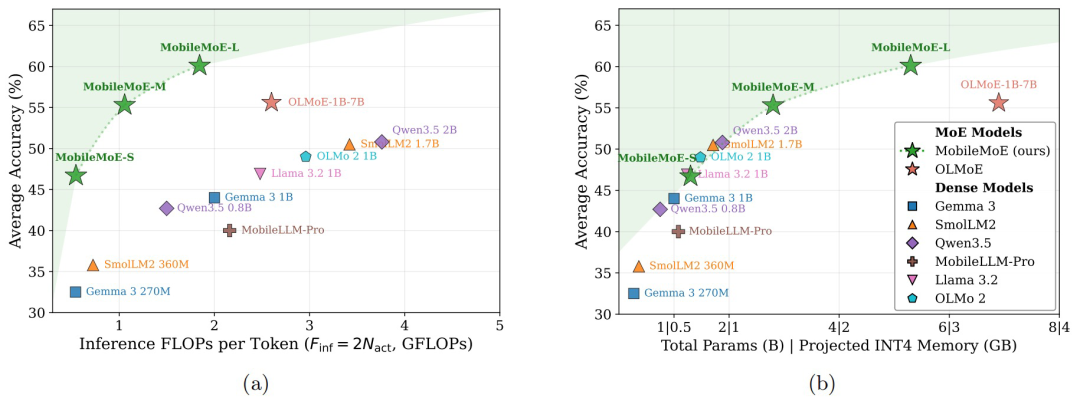
研究团队在常识推理、知识、科学、阅读、推理五类共14项基础评测中,将MobileMoE与Gemma 3、SmolLM2、Qwen3.5、OLMo 2、OLMoE等模型统一重测。结果显示:
- MobileMoE-M平均分高于Qwen3.5 2B,MobileMoE-L平均分高于OLMoE-1B-7B,且模型规模更小。
- MobileMoE-L的Base版本平均分已高于OLMoE-1B-7B的Instruct版本。
- 训练数据量仅约6T tokens,少于Llama 3.2 1B的9T和SmolLM2 1.7B的11T。
- 指令微调后,MobileMoE-M平均准确率接近OLMoE-1B-7B,但活跃参数和总参数都少约60%。
- 在代码和数学任务上,MobileMoE-L高于Qwen3.5 2B和OLMoE-1B-7B;但在指令跟随和知识推理上Qwen3.5 2B仍占优。
iPhone 16 Pro实测:输入阶段3.8倍提速,内存更省
量化实验中,MobileMoE-S/M/L的INT4版本相比BF16版本平均分仅下降2~3分,但MobileMoE-L INT4版本表现仍高于OLMoE-1B-7B Instruct的BF16版本。实际端侧部署测试更显实力:
- 在iPhone 16 Pro的GPU/MLX后端,MobileMoE-S相比MobileLLM-Pro,输入阶段提速1.8~3.8倍,逐token生成阶段提速2.2~3.4倍。
- 在Samsung Galaxy S25上,8K上下文且真实prompt条件下,MobileMoE-S峰值RSS仅1.49GB,低于MobileLLM-Pro的1.91GB,内存占用更低。