算力租赁,头部玩家的暴富赛道

Token消耗狂飙 算力租赁从“卖时间”到“卖Token”
截至2026年4月初,全球AI大模型词元(Token)总调用量已达27万亿,环比增长18.9%,中国调用量已连续五周超越美国。每一笔Token消耗背后,都是GPU在发热、电力在燃烧——这正是算力租赁最底层的增长引擎。
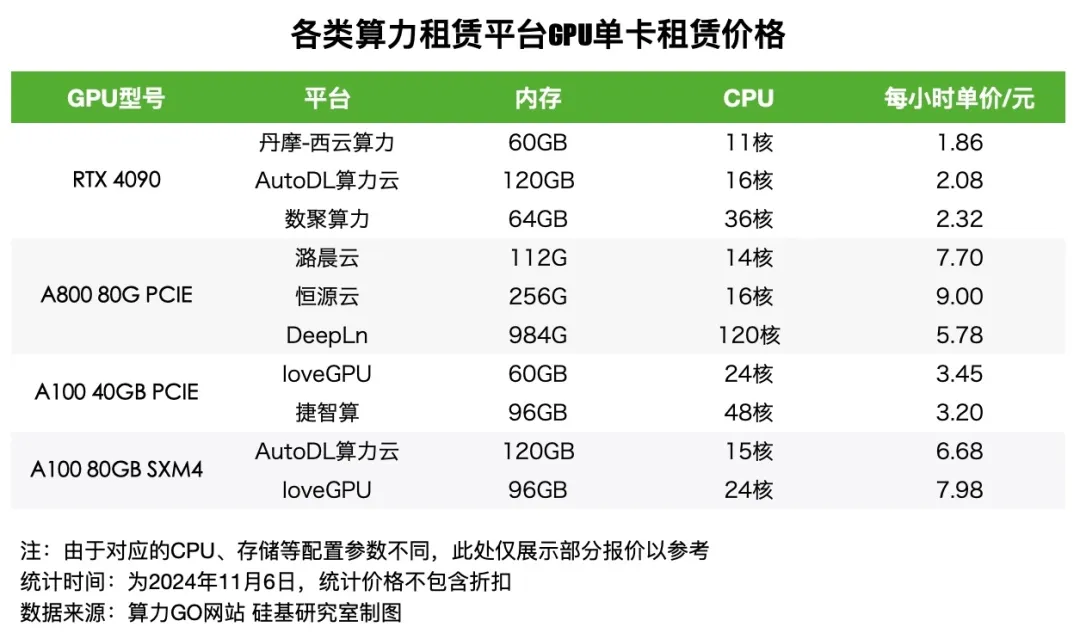
曾经“买卡自建”是AI企业的唯一选择,但单张英伟达A100售价高达10-15万元,H100更飙至20-30万元,对于初创公司而言,仅硬件成本就足以压垮。如今,“以租代买”在中小企业中迅速普及,可降低70%以上初期投入,还能随时换新。在中国部分电脑设备租赁企业,高性能机型甚至出现“上架即秒光”的火爆行情。
更关键的是,行业的计价模型正在发生根本性跃迁:从“卖算力”(按GPU小时收费)转向“卖Token”(按模型调用量计费)。企业不再关心自己用了多少小时GPU,只关心模型能生成多少Token。算力租赁厂商的服务交付方式也随之从“裸算力出租”升级为“模型服务即算力”乃至“Token分成模式”,利润空间被指数级放大。
价格端最直观的佐证:H100一年期租赁合同价从2025年10月每卡每小时1.70美元的低点,急升至2026年3月的2.35美元,涨幅接近40%。H200时租金达7.5元至8.0元/卡时,月租涨至6万-6.6万元,涨幅25%-30%;交付周期已大幅延长至2027年第二季度。市场的紧张程度可见一斑。
字节豆包开收会员 背后算力账单惊人
5月4日,字节跳动旗下AI应用豆包在App Store新增付费版本,推出标准版68元/月、加强版200元/月、专业版500元/月三档服务,聚焦PPT生成、数据分析等高复杂度场景。豆包为何此时收费?三个数字说明一切:豆包日均Token消耗量已达120万亿,相比2024年5月首次发布时增长1000倍,2026年头三个月又翻了一番;字节跳动2026年规划资本开支约1600亿元,预计一半投向AI芯片;业内测算推理算力需求已是训练阶段的10-15倍。付费用户越多、任务越复杂,算力消耗就越快——这套逻辑闭环的终端传导效应,就是算力租赁厂商接单到手软。
一场122天建成的超级数据中心租约
如果说豆包付费体现的是需求倒逼,那么Anthropic与SpaceX的算力大单则实打实展示了供给格局的重塑。5月6日,AI独角兽Anthropic正式租下SpaceX旗下位于美国田纳西州孟菲斯的Colossus 1数据中心全部算力。该数据中心配备超过22万块英伟达GPU,包括H100、H200乃至下一代GB200加速器,总功耗达300兆瓦,相当于一个约20万至30万户家庭的中型城市居民用电量。从规划到建成仅用了122天,充分体现SpaceX的工程统筹能力。
对Anthropic而言,一个月内即可获得超过300兆瓦新增算力,总算力从不足10万张H100当量一举追平OpenAI、Google DeepMind。对SpaceX来说,原本为xAI训练Grok而建的Colossus 1在xAI解散并更名后处于闲置状态,租给Anthropic不仅实现了闲置顶级算力的直接变现,还为即将到来的IPO贡献了极具说服力的现金流故事。两家公司甚至已在探讨合作开发“数吉瓦级的轨道AI算力”。
值得注意的是,Anthropic并非只租一家。此前一个月,它已分别与亚马逊和谷歌/博通签订了总计约5吉瓦的算力协议,仅与谷歌的5吉瓦协议就相当于5年内投资近2000亿美元。再加上与微软Azure签订的300亿美元合同,Anthropic在算力承诺上的总规模已达数千亿美元。现实揭示:顶尖AI模型的竞争不仅是算法和数据竞赛,更是纯粹的算力消耗战,而最有实力的不是模型厂商,而是手握海量GPU资源的“算力王者”。
一季度净利暴增821%,算力“包租公”们赚翻了
国内算力租赁市场的业绩爆发力同样惊人。利通电子2026年第一季度归母净利润达2.7亿元,同比增长821%;协创数据同期归母净利润7.5亿元,同比增长343%。东阳光在2026年5月5日公告,其控股子公司签署的算力服务采购框架合同订单总金额达到160亿至190亿元。
放眼海外,新兴云厂商CoreWeave的资本开支计划从103亿美元跳升至300亿至350亿美元,在手订单规模逼近960亿美元;甲骨文与OpenAI达成的4.5GW算力租赁协议,将其2026年资本开支直接上调至500亿美元以上。甲骨文FY26Q3云基础设施收入同比高增84%达48.88亿美元,剩余履约义务(RPO)高达5530亿美元,同比增长325%。
行业头部公司已跑通“拿卡-锁价-租赁-提价-长单锁定”的完整盈利闭环。国内算力租赁市场份额前五名(CR5)已升至60%以上,中小厂商因芯片渠道匮乏、交付能力不足加速出清。高端算力(英伟达H100/H200、华为昇腾910等)处于严重供需失衡状态,头部厂商算力上架率普遍超90%,订单排期已至2027年。
赢家通吃:技术迭代的“诅咒”与租赁模式的“反脆弱”
英伟达正以惊人节奏更新产品路线图:Blackwell之后,Vera Rubin平台承诺今年下半年出货,性能功耗比达前代10倍;Rubin Ultra预计2027年问世,Feynman计划2028年推出。每一代GPU算力跃升都意味着旧代服务器账面价值快速缩水,这对投入数千亿购置固定资产的算力租赁企业带来折旧和资产减值风险。但恰恰因此,租赁模式体现出更强的商业韧性——唯有通过大批量、快速迭代的集群运营,才能将硬件更新成本平滑分散到大量客户身上。正如梅赛德斯-奔驰F1车队不会因为明年要换新引擎就不参加今年的锦标赛,AI企业不会因为明年的硬件更强就不租用今天的GPU。在技术加速迭代下,算力租赁不亏反赚——租户无需担心资产贬值,出租方靠规模效应消化迭代成本。
国产算力面临“缺芯少魂”的结构性烦恼。在中国部分智算中心,安装了英伟达GPU的机柜出租率超过90%,而国产GPU服务器出租率很低。核心瓶颈在于软件生态:CUDA沉淀了十数年的开发者工具链,国产GPU在框架适配、编译优化上仍有明显差距。华泰证券判断2026年是“国产超节点元年”,试图通过系统级重构弥补单芯片差距。工信部已印发《关于开展普惠算力赋能中小企业发展专项行动的通知》,支持“算力银行”“算力超市”等创新业务,但若基础算力底座仍以海外高端芯片为主,所谓的“普惠算力”在深层供给上仍受制于外部供应链不确定性。
当前热潮主要由互联网大模型企业推动,Token指数级增长多集中在云端应用和智能体赛道。真正的算力大航海时代尚未到来——智能制造、医疗影像、自动驾驶、数字孪生等实体行业如全面拥抱AI,算力需求井喷量级将再翻数倍。算力租赁行业面临选择:是继续追逐头部大客户“赚快钱”,还是主动下沉与各行业深度合作“赚大钱”?后一条路需要耐心、产业认知和跨领域协同能力。
AI的免费时代正在加速终结。算力作为最刚需、最稀缺的生产资料,其“租赁者”正成为这场产业浪潮中确定性最强的受益者。当AI付费潮从C端应用向B端基础设施层层传导,算力租赁不再是某个细分赛道的边缘生意,而是整个AI产业商业闭环中不可或缺的“水电煤”。