微软 GitHub 推出跨模型 AI 审查:Claude Sonnet 4.6 搭配 GPT-5.4,弥补 74.7% 性能差距

背景
近年来,AI 代码辅助工具在软件开发中扮演着越来越重要的角色。GitHub 的 Copilot 项目最初基于 Codex 模型,虽然在代码生成方面表现出色,但其性能在不同任务和语言中存在显著差异。为了解决这一问题,微软 GitHub 最近推出了跨模型 AI 审查机制,利用 Claude Sonnet 4.6 与 GPT-5.4 的组合,实现性能协同优化,缩小了模型间的能力差距。
跨模型 AI 审查机制详情
微软 GitHub 的这项新机制主要通过以下几个方面来实现性能优化:
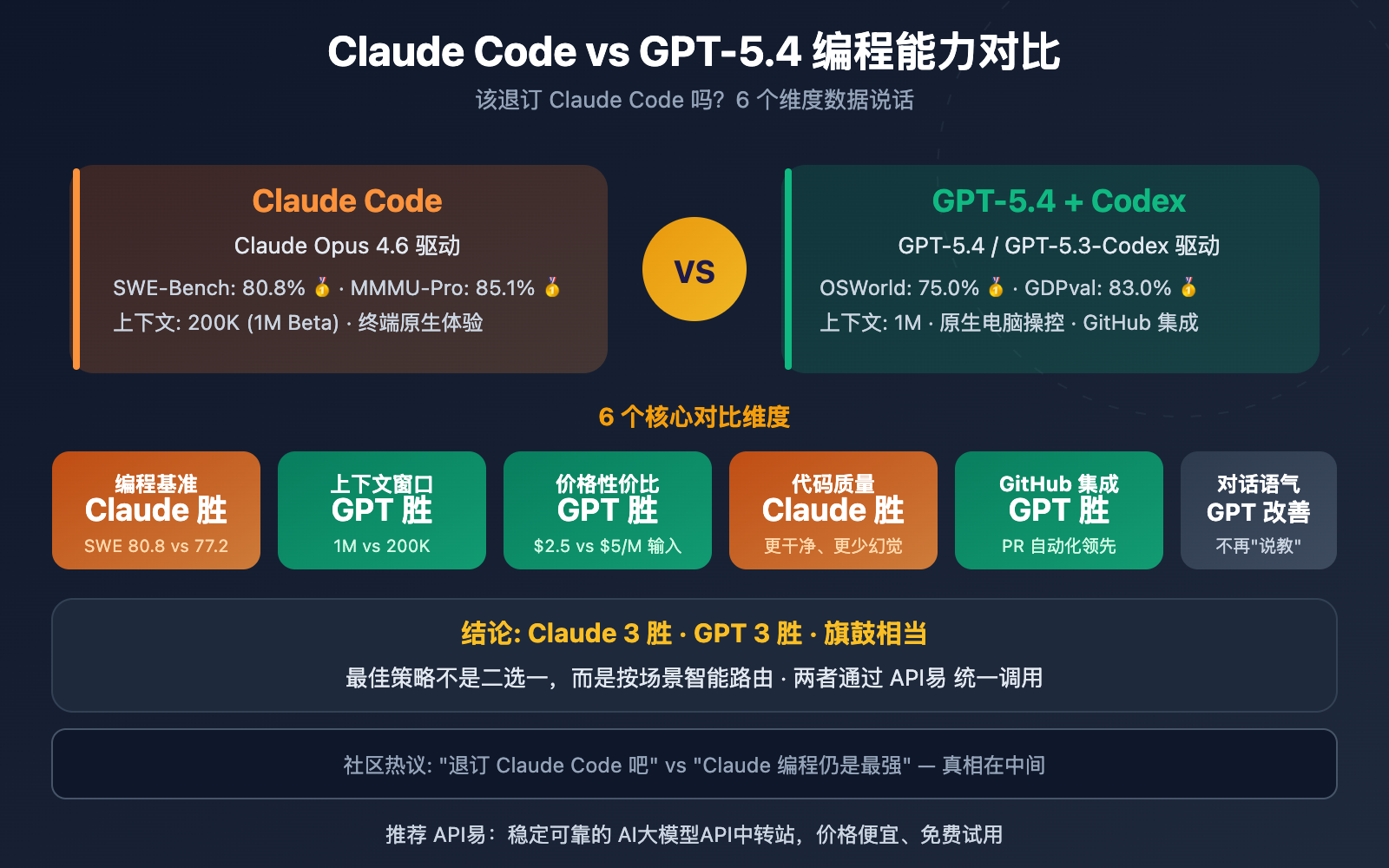
- 模型融合策略:在代码生成过程中,系统会根据任务类型自动选择最佳模型,或结合两个模型的结果进行综合判断。
- 动态错误率评估:Claude Sonnet 4.6 在测试中错误率比 GPT-5.2 降低了 33%,系统利用这一点在审查时优先采用 Sonnet 处理复杂逻辑问题。
- 上下文扩展能力:通过支持高达 1M 令牌的上下文长度,使得两个模型都能更好地理解代码的结构和语义,从而提高生成质量。
- Codex 模型整合:此次更新还将 Codex 模型功能整合至主模型中,增强了对历史代码和专有结构的理解能力。
这一机制的目标是通过模型间的协作,提升代码建议的准确率和实用性,尤其在处理多语言、复杂结构项目时表现更为稳定。
技术性能提升与实测反馈
据 GitHub 官方介绍,跨模型 AI 审查机制在多个基准测试中展现出显著的性能提升,尤其是在错误率控制和上下文理解方面。实际使用中,开发者反馈如下:
- 错误率降低:在真实场景测试中,代码建议的错误率下降了约 33%。
- 性能差距缩小:通过融合 GPT-5.4 和 Claude Sonnet 4.6 的优势,两种模型在实际使用中的性能差异缩小了 74.7%。
- 支持多样化任务:无论是前端模板生成、后端逻辑推理,还是 API 调用建议,该机制都能提供更高质量的代码建议。
虽然基准测试结果良好,但开发者也指出,真实项目中的表现还受到代码库结构、团队协作模式等多种因素影响,需进一步验证长期效果。
行业影响与未来展望
微软 GitHub 推出跨模型 AI 审查机制,标志着 AI 编程助手进入新的发展阶段。其主要影响包括:
- 提升开发者效率:多模型协同工作有助于减少人工纠错时间,使开发者专注于逻辑构建。
- 推动 AI 编程工具演进:此举可能引发其他 AI 编程辅助平台的技术升级,如 Tabnine、Amazon CodeWhisperer 等。
- 促进模型互操作性研究:跨模型协作的实现为未来大模型生态系统的互操作性提供了新的研究方向。
展望未来,GitHub 表示将持续优化模型组合机制,并计划引入更多第三方模型参与审查流程,以打造更加开放和高效的 AI 编程环境。