一周3.3k star,微软开启Skills自我进化,像训练神经网络一样训练技能

52个评测组合全最优:SkillOpt掀起技能训练革命
在7个目标模型、6个基准测试、3种执行环境(直接对话、Codex、Claude Code)的全部52个评测组合中,SkillOpt训练出的技能文档全部达到最优或并列最优。这一覆盖范围从模型种类到应用场景的全面胜利,证明了即便不修改模型底层权重,仅通过优化自然语言技能文档,也能让AI Agent的决策质量大幅跃升。无论是处理复杂编程任务还是多轮对话,SkillOpt产出的技能描述都表现出惊人的泛化能力。
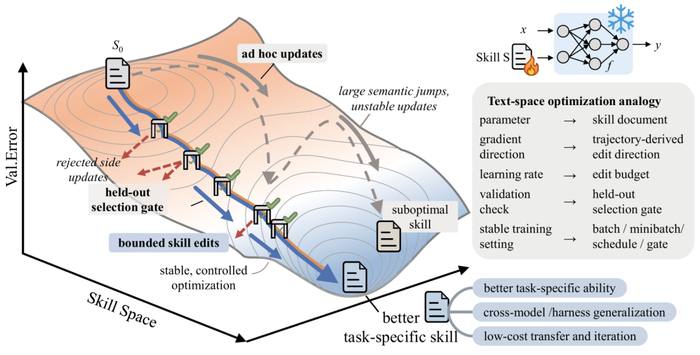
不碰模型权重,只优化自然语言文档
SkillOpt最巧妙的设计在于:整个进化过程完全不需要触碰或修改大模型的底层权重。核心思路非常直观——将那份指导Agent行为的自然语言文档当作“可训练参数”,在文本空间中进行优化。这意味着开发者无需重新训练或微调昂贵的模型,只需像迭代代码一样修改技能说明,就能让Agent适应新场景。这种“轻量级”定制彻底打破了传统Agent技能开发的高门槛。
设定轮次批大小学习率:像训练神经网络一样调参
微软将神经网络的训练范式直接迁移到文本空间:设定训练轮次(Epoch)、批大小(Batch Size)和学习率(Learning Rate),让技能文档在每次迭代中自我进化。例如,通过调整学习率控制文档改写的幅度,避免过度优化或陷入局部最优;批大小则影响每次采样多少个历史成功案例来引导改进方向。这套框架让开发者能像调优神经网络超参数一样,精准控制技能文档的训练过程,最终输出高稳定性的Agent行为指南。
一周狂揽3.3k星:开发者社区热捧
SkillOpt在GitHub开源后短短一周内斩获3.3k星,迅速成为AI工程化领域的热门项目。开发者们纷纷表示,这项技术解决了以往Agent长尾任务难以精细调优的痛点——无需理解底层模型细节,只需优化一份可读的文档,就能持续提升Agent表现。随着社区贡献更多迁移学习策略和环境评测数据,SkillOpt有望成为下一代Agent技能自动优化的标准工具。