开源模型首超Opus4.6!智谱GLM-5.1登场,14小时后CUDA专家被冲了

背景与行业趋势
近年来,AI大模型的发展已经从简单的对话能力,逐步演进为能够完成复杂工程任务的“执行者”。过去衡量模型智能程度的主要标准是跑分,例如在SWE-bench Pro等代码评测基准上的表现。然而,随着模型能力的提升,行业逐渐意识到,仅靠跑分已无法全面反映AI模型的实用价值。
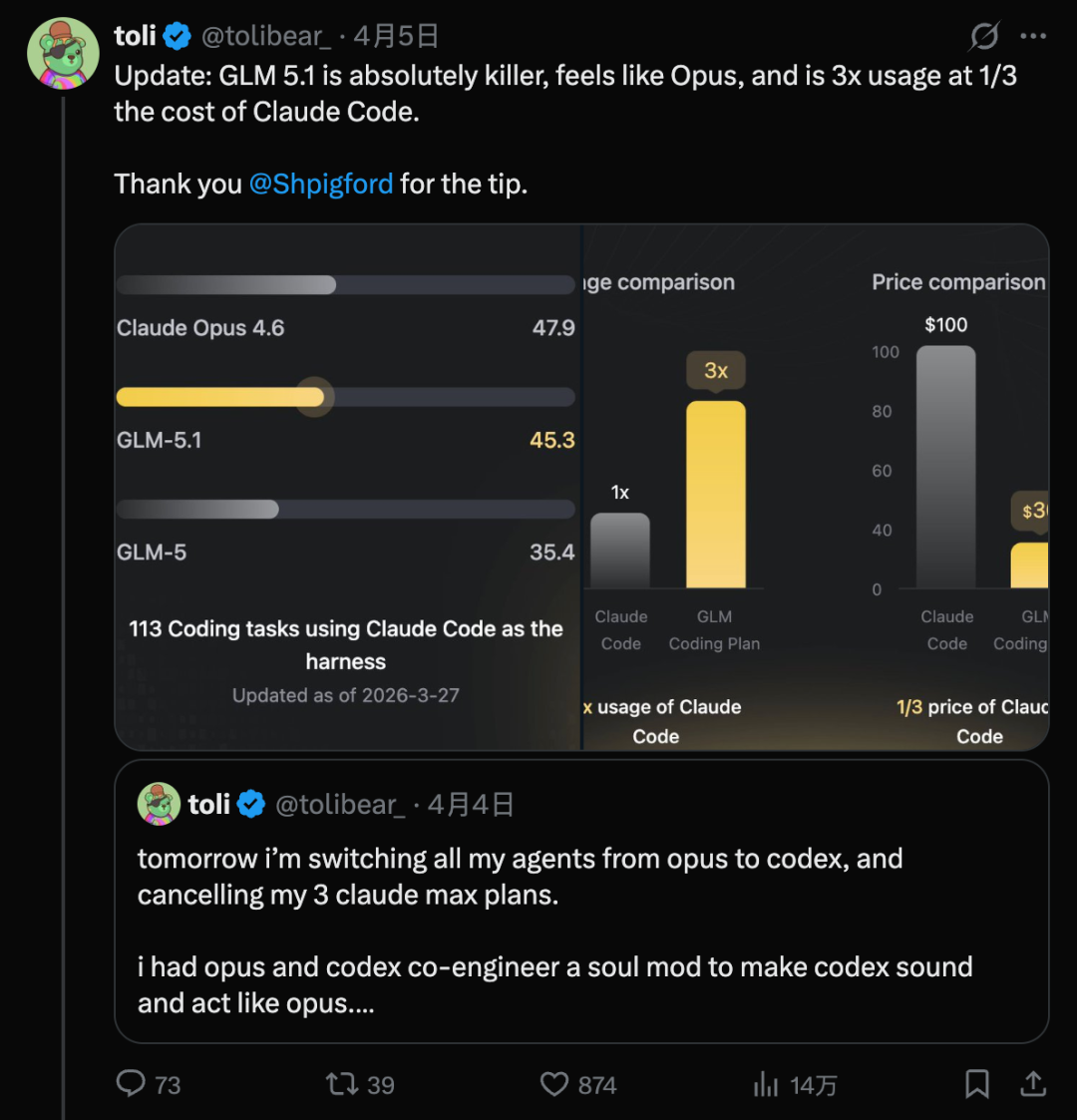
智谱AI推出的GLM-5.1,正是在这一趋势下诞生的里程碑式开源模型。它不仅在多项评测中超越GPT-5.4与Claude Opus 4.6,更在“长程任务(Long Horizon Task)”处理能力上实现了突破。GLM-5.1能在单次任务中持续、自主工作长达8小时,最终交付完整的工程级成果。
技术突破与模型特性
GLM-5.1的核心优势体现在以下几个方面:
- 744B MoE架构:采用混合专家模型,每个token激活40B参数,兼顾模型容量与推理效率。
- 200K长上下文:支持最大输出131,072 tokens,满足复杂工程任务中长期记忆与上下文跟踪需求。
- DSA稀疏注意力机制:结合DeepSeek Sparse Attention,显著降低部署成本。
- 全栈优化能力:从编译、测试、分析到重写,GLM-5.1能够自主闭环完成复杂迭代。
在壁仞科技的配合下,GLM-5.1成功实现高效推理,依托其高算力芯片与BIRENSUPA™软件栈,进一步释放了模型潜力。
实测表现与工程能力
GLM-5.1在多个真实工程场景中的表现令人惊叹:
- CUDA Kernel优化:AI在14小时内完成资深CUDA工程师通常需要数月的优化任务,加速比从2.6×提升至35.7×。
- 1小时构建MacOS桌面环境:基于3000字PRD,AI完成从零开始的UI复刻与系统功能实现,相当于4人团队一周的工作量。
- 自动重构“屎山”代码:将混乱、低效的代码优化为结构清晰、符合规范的代码,大幅提升可维护性。
- 向量数据库性能优化:通过655轮自主迭代,将查询吞吐量提升6.9倍,展现了极强的持续学习与优化能力。
这些实测不仅展示了GLM-5.1在软件开发领域的潜力,也揭示了AI正在逐步承担更复杂的任务闭环。
性能对比与行业认可
GLM-5.1在权威评测中表现突出:
- SWE-Bench Pro:得分58.4%,超越Claude Opus 4.6(57.3%)与GPT-5.4(57.7%),刷新全球最佳成绩。
- Terminal-Bench 2.0与NL2Repo:三项综合平均分,GLM-5.1位列全球模型第三、国产模型第一、开源模型第一。
- MIT METR测试:在任务完成时间线(Task-Completion Time Horizon)评测中,GLM-5.1是唯一实现8小时持续工作的开源模型。
HuggingFace CEO Clement Delangue也公开表示:“SWE-Bench Pro上表现最好的模型现在在HuggingFace上开源了!欢迎GLM-5.1。”
影响与未来展望
GLM-5.1的推出,标志着国产开源模型在全球AI竞争格局中迈出了关键一步。它不仅打破了“中国模型只能追赶美国闭源模型”的刻板印象,更以开源的形式推动全球AI开发者共同进步。
- 算力成本降低:开发者Beau Johnson将模型从Claude Opus切换为GLM-5.1后,成本从1000美元降至30美元,降低了97%。
- 推动AI普惠化:开源意味着更低的使用门槛,任何人都可以部署、修改、优化GLM-5.1,为AI生态注入更多活力。
- 重塑软件工程逻辑:当AI能持续数小时完成复杂任务时,传统人力配置与行业定价模式将面临重构。
尽管在推理速度(44.3 tokens/秒)等方面仍有提升空间,GLM-5.1的意义在于它证明了:在算力受限的环境下,中国开源模型依然可以做到全球领先。
未来,AI不再只是辅助工具,而是真正的“执行者”。GLM-5.1的出现,不仅是技术进步,更是一场生产力的变革。它将推动AI从“对话者”向“工程师”演进,成为真正能够改变世界的力量。