智谱 GLM-5.1 高速版 AI 模型发布,跑出全球最快速度 400 tokens/s

速度翻倍至400 tokens/s,刷新开源大模型推理极限
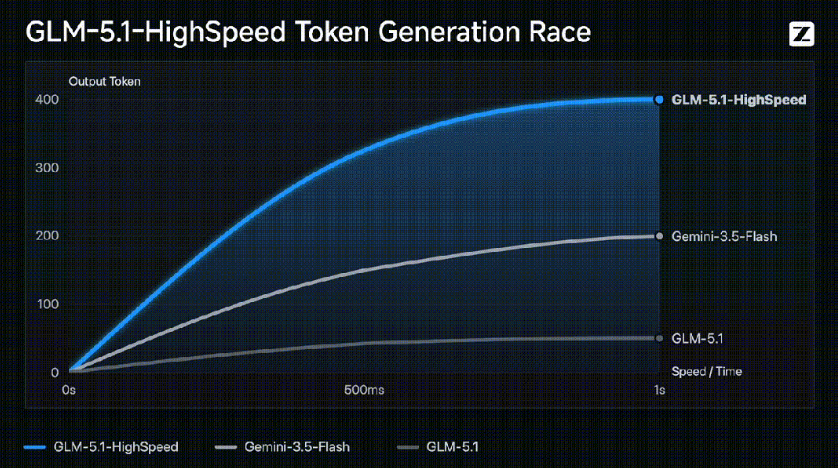
此次发布的GLM-5高速版并非单一模型,而是一系列以极致速度著称的旗舰产品。其中,推理模型GLM-Z1-32B-0414率先实现了高达 200 tokens/秒 的实测推理速度,智谱方面宣称这已经是目前国内商业模型中速度最快的。而更令人瞩目的是,针对智能体场景优化的 GLM-5-Turbo 版本,输出速度更是直接飙升至 400 tokens/s,这一数字在全球范围内都属顶尖。这不仅意味着更低的用户等待时间,也为大模型在实时交互、自动驾驶、高频交易等对延迟有严苛要求的领域提供了可能。
- 实测速度对比:GLM-Z1-32B-0414 达 200 tokens/秒,GLM-5-Turbo 更高达 400 tokens/秒。
- 定位优势:在保持高性能的同时,实现了国内商业模型中的速度领先。
- 服务体验:与此前发布的API调用价格极低的 GLM-4.5(API调用价格仅0.8元/tokens,输出速度可达100 tokens/s)相比,速度提升了数倍。
编程与智能体任务比肩Claude Opus,实现开源模型新SOTA
速度是亮点,性能更是核心。GLM-5 系列模型在极其困难的编程基准测试 SWE-bench Verified 以及 Terminal Bench 2.0 等智能体编程核心榜单上,取得了开源模型领域的最强性能(SOTA)。其中,GLM-5 在编程基准测试中得分高达 54.9分,仅落后于全球顶尖闭源模型 Claude Opus 4.6 仅 三分。这一表现证明,国产开源模型在复杂代码生成、逻辑推理与长链执行能力上,已经真正跻身世界第一梯队,具备了挑战主流商业闭源模型如DeepSeek-R1的实力。
- 硬核成绩:SWE-bench Verified、Terminal Bench 2.0 榜单开源 SOTA。
- 对标国际:性能比肩 Claude Opus 4.6 等全球顶尖模型。
- 技术突破:实现了性能与DeepSeek-R1等顶尖模型相媲美的水平。
128K超长上下文与开源生态,助力企业级智能体应用落地
GLM-5 高速版并不仅仅是跑得快、算得好,其核心设计理念是为“智能体(Agent)”而生。GLM-5-Turbo 专为 OpenClaw 等商用场景优化,原生支持高达 128K 输出Token 和 200K 上下文长度,极大地提升了智能体在复杂任务规划、跨应用协作以及长链执行中的效率与稳定性。为了推动Agent生态发展,智谱还开源了用于操作PC的基座模型 CogAgent-9B,该模型仅需屏幕截图即可完成复杂操作。这些举措共同构建了从底层模型到上层应用的完整闭环,为企业提供了高效、稳定且成本友好的AI智能体开发套件。
- 超长上下文:GLM-5-Turbo 支持 128K 输出 Token,200K 上下文长度。
- 智能体优化:增强工具调用、长链执行能力,提升任务执行效率与稳定性。
- 开源生态:开源 CogAgent-9B 基座模型,赋能终端智能体应用。
- 全流程开发:提供模型微调、AI搜索等一站式开发套件,加速企业级AI落地。