阿里千问 App、PC 端及网页端接入全新一代大模型 Qwen3.7-Max

三步切换,免费畅享最强千问智能体
即日起,用户可通过以下方式立即体验Qwen3.7-Max的强大能力:
- 移动端:将千问APP更新至最新版(6.9.7及以上),点击对话界面底部胶囊按钮“Qwen3.7-Max”即可切换。
- PC端及网页端:在对话界面的“模型选择栏”中下拉选择“Qwen3.7-Max”,全程免费,无需额外申请。
该模型已在Artificial Analysis等三方机构公布的最新全球大模型榜单中获得认可,成为国产模型中表现最亮眼的新一代旗舰。
编程与推理能力全面突破,35小时超长任务自主完成
Qwen3.7-Max在设计上专为智能体时代打造,核心能力实现跨越式提升:
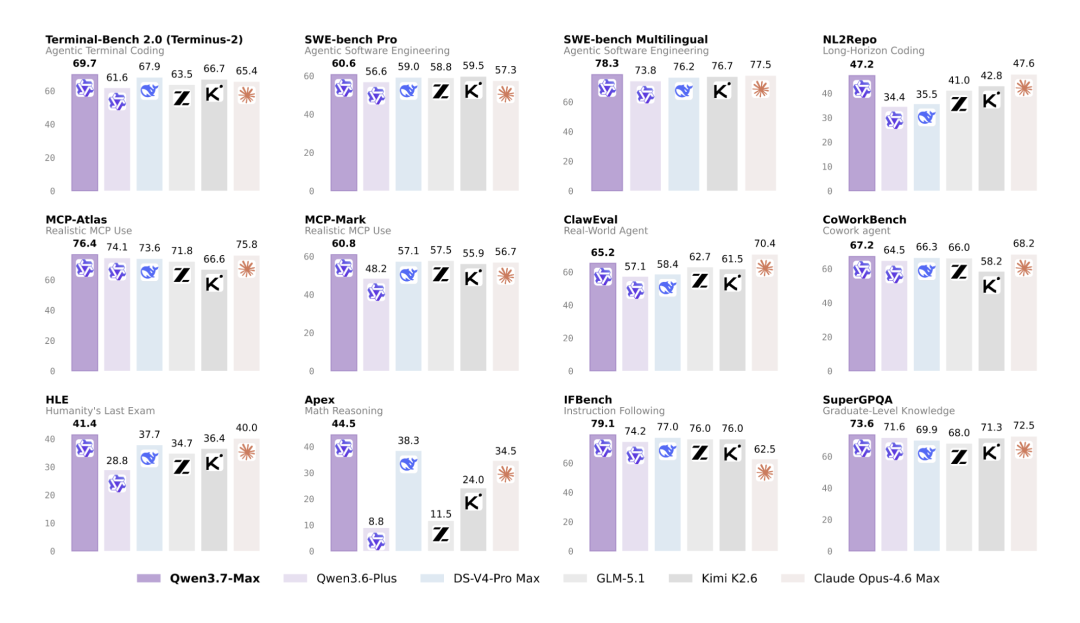
编程智能体:在多项权威评测中取得领先
- SWE-Pro得分60.6,SWE-Multilingual得分78.3,SciCode得分53.5,QwenSVG得分1608。
- 在Terminal Bench 2.0-Terminus上以69.7分超越DS-V4-Pro Max(67.9),SWE-Verified得分80.4,与Opus-4.6 Max(80.8)相当。
通用智能体:自主规划与跨工具协作能力显著
- MCP-Mark得分60.8(优于GLM-5.1的57.5),MCP-Atlas得分76.4(优于Opus-4.6的75.8),Skillbench得分59.2(优于K2.6的56.2)。
- 在Kernel Bench L3上实现1.98倍中位数加速,96%加速率,展示出GPU内核优化能力;办公自动化基准SpreadSheetBench-v1得分87.0,处于顶尖水平。
- 可全自主完成35小时超长程智能体任务:在一个全新芯片平台上,通过自主编程和超1000次工具调用,实现关键内核自我进化,推理速度较原版本提升10倍。
推理与通用能力:数学、逻辑、多语言全面领先
- GPQA Diamond得分92.4(优于Opus-4.6的91.3),HLE得分41.4(优于Opus-4.6的40.0),HMMT 2026 Feb得分97.1(优于Opus-4.6的96.2),IMOAnswerBench得分90.0,Apex得分44.5。
- IFBench得分79.1(指令遵循能力),WMT24++得分85.8(多语言翻译),MAXIFE得分89.2,SuperGPQA得分73.6,QwenWorldBench得分57.3。
盲测国产第一,智能体范式转换拉开序幕
在第三方机构Arena全球大模型盲测总榜中,Qwen3.7-Max超越Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1,与GPT、Claude、Gemini最强模型接近,位列国产模型第一。
阿里巴巴通义大模型事业部负责人周靖人指出,大模型正经历核心范式转移——从“对齐人类偏好”转向“对齐任务目标”。过去追求模型“说得好”,现在要求模型“做得到”。Qwen3.7-Max正是为此设计,成为Agent的智能内核,具备自主规划、持续迭代、跨工具协作的能力。
该模型已通过阿里云百炼提供API调用,后续还将推出Qwen3.7-Plus等版本,覆盖从编程智能体到视觉智能体的全场景需求。