内存暴降50倍且精度无损,MIT提出注意力匹配,能终结大模型显存危机吗?

KV Cache吃掉90%显存?MIT用新算法解围
大模型推理时,一个巨大的难题是KV cache(键值缓存)的消耗。简单来说,模型每生成一个Token,都要记录之前所有Token的Key和Value向量,这些缓存随着序列长度的增加而线性膨胀,最终占据推理时90%以上的显存,使得长上下文(如百万Token)几乎无法在消费级显卡上运行。MIT研究人员提出的Attention Matching(注意力匹配)技术,直接向这个痛点宣战——他们声称能将KV cache压缩整整50倍,且精度保持与未压缩版本几乎一致。
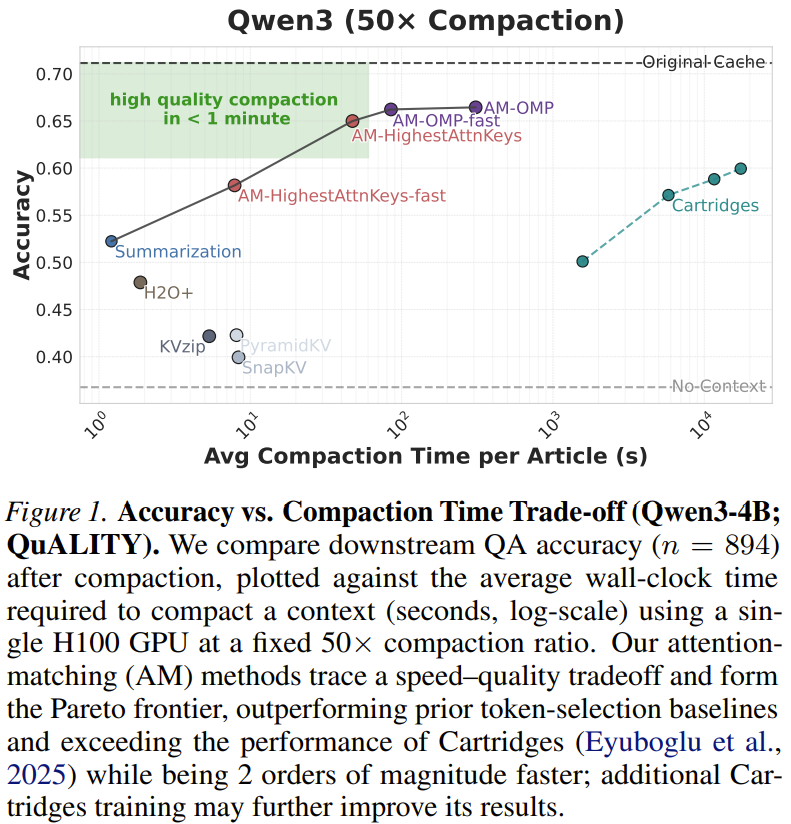
精度无损的50倍压缩是如何做到的
传统压缩KV cache的方式往往采用量化(如4bit、2bit)或剪枝,但会引入明显的精度损失。MIT的Attention Matching另辟蹊径:它并不粗暴地压缩存储的数值,而是通过一个轻量级“匹配器”,在推理时动态地将原始注意力模式“匹配”到一个极度压缩的表征空间中。这个匹配过程高度近似原始注意力计算,却只需要极少的参数量和缓存空间。实验表明,在多个主流模型(包括LLaMA系列)和长文本基准测试上,采用Attention Matching后,模型的困惑度、下游任务准确率与全精度版本相差不到0.5%,而显存占用却从数GB级降至几十MB级。
从理论到落地:大模型部署的曙光
这项突破最直接的应用场景是端侧部署和长对话服务。例如,此前要将支持128K上下文的模型塞进手机或边缘设备,几乎不可能;现在有了50倍压缩,一张消费级显卡就能运行百万Token级别的模型,而无需依赖昂贵的A100/H100集群。更关键的是,Attention Matching在推理速度上也有优化——由于缓存体积骤减,显存带宽瓶颈得到缓解,实际生成速度甚至可能反超未压缩版本。MIT团队已开源其代码,社区纷纷将其与谷歌同日发布的TurboQuant算法对比,但普遍认为Attention Matching在压缩比和精度保持上更具突破性。
Attention Matching会是显存危机的终结者吗?
虽然50倍压缩非常惊艳,但仍有挑战需要解决:该技术在训练阶段需要额外训练一个注意力匹配器(不过成本远低于预训练),且对于极端长序列(如超过100万Token)的泛化性尚未充分验证。不过,MIT的成果已经证明:大模型的显存危机并非无解。随着Attention Matching与量化、稀疏化等技术进一步融合,未来或许很快就能看到数百亿参数的大模型在手机或笔记本上流畅运行,真正终结“显存不够用”的噩梦。