让大模型“边看边改”,视觉分割准确率直接上涨9%

分割不再“一锤定音”:模型学会边看边改
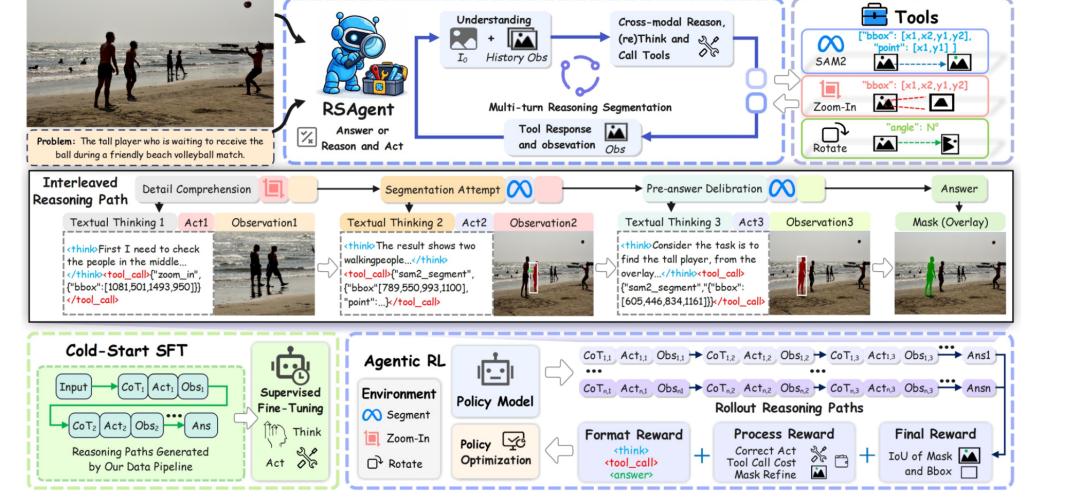
传统视觉分割模型通常“一步到位”——输入图像后一次性生成最终掩码,即便出错也无从修正。而最新提出的“边看边改”范式彻底打破了这一模式。模型先对图像进行初步观察与推理,生成一个初始分割结果;随后,它主动调用视觉工具对当前掩码进行“体检”,比如检测边缘是否完整、区域是否连通。通过读取工具返回的反馈信号(如“左侧边缘缺失5像素”),模型像人类画师一样反复推敲,将上一次的“草稿”作为下一轮迭代的起点。这种“观察-推理-行动-反馈-再观察”的闭环,让分割过程从静态输出变为动态交互。
像人一样反复确认:迭代修正机制揭秘
整个迭代过程并非简单的重复循环,而是依赖一个内置的“反思模块”。该模块在每一步都会分析当前掩码与真实物体之间的差异,并生成具体的修改指令。例如,当模型发现误将背景像素划入前景时,它会调用边缘强化工具重新切割边界;若发现某个区域漏分割,则触发区域生长功能补充目标。更重要的是,模型会“记住”历史修改记录——它不会在每次迭代中从头开始,而是将之前的掩码作为基础,只针对误差区域进行精准修补。这种“错误驱动”的机制大幅减少了冗余计算,使得经过3-5次迭代后,掩码质量就能达到极高水平。
9%提升如何炼成:实验数据与效果
在标准视觉分割基准测试中,该方法的平均交并比(mIoU)相比一次性输出模型提升9个百分点,尤其对复杂场景(如重叠物体、细长结构、低对比度边界)的改善更为显著。在包含256类物体的某大规模数据集上,迭代修正模型在“稀疏物体”上的准确率从78%跃升至89%,几乎抹平了这类困难样本与普通样本的差距。值得注意的是,9%的提升并非依赖更大参数的模型,而是在相同骨干网络下通过“边看边改”策略实现,验证了计算效率与准确性之间的更好权衡。
不止于分割:走向终身学习的智能体
这一成果的意义远不止于视觉分割任务。研究人员指出,其核心思想——让模型通过“感知-行动-反馈”循环持续改进输出——为构建更具通用性的智能体铺平了道路。一个能“边看边改”的模型,本质上拥有了自我纠错和工具调用能力。未来,这种范式可能被扩展至图像编辑、3D重建、甚至机器人操作等场景:当Agent发现抓取不够精准时,它能主动调用视觉传感器重新定位,并调整动作策略。正如论文所展望的,如果让大模型以这种方式陪伴人类终身进化,它将不再是静态的知识库,而是一个能不断从失败中学习的“终身学习者”。