让莘莘学子夜不能寐的AIGC检测,到底是什么

卧薪尝胆的学生们:AI写作的诱惑与风险
一方面,AI大模型为莘莘学子提供了“葡萄汁”般甜美的便捷——几分钟生成一篇结构完整的论文,省去挑灯夜战之苦。另一方面,这种“抄近道”的行为正在被精准狙击。不少学生像古代“卧薪尝胆”的勾践一样,试图通过反复改写、混合语序来躲避检测,但往往验证了“落花流水”般徒劳——因为AIGC检测工具远比想象中敏锐。
落花流水:AIGC检测如何“抓现行”
AIGC检测的本质是分析文本的“非人类”特征。常见的算法会从三个维度下手:
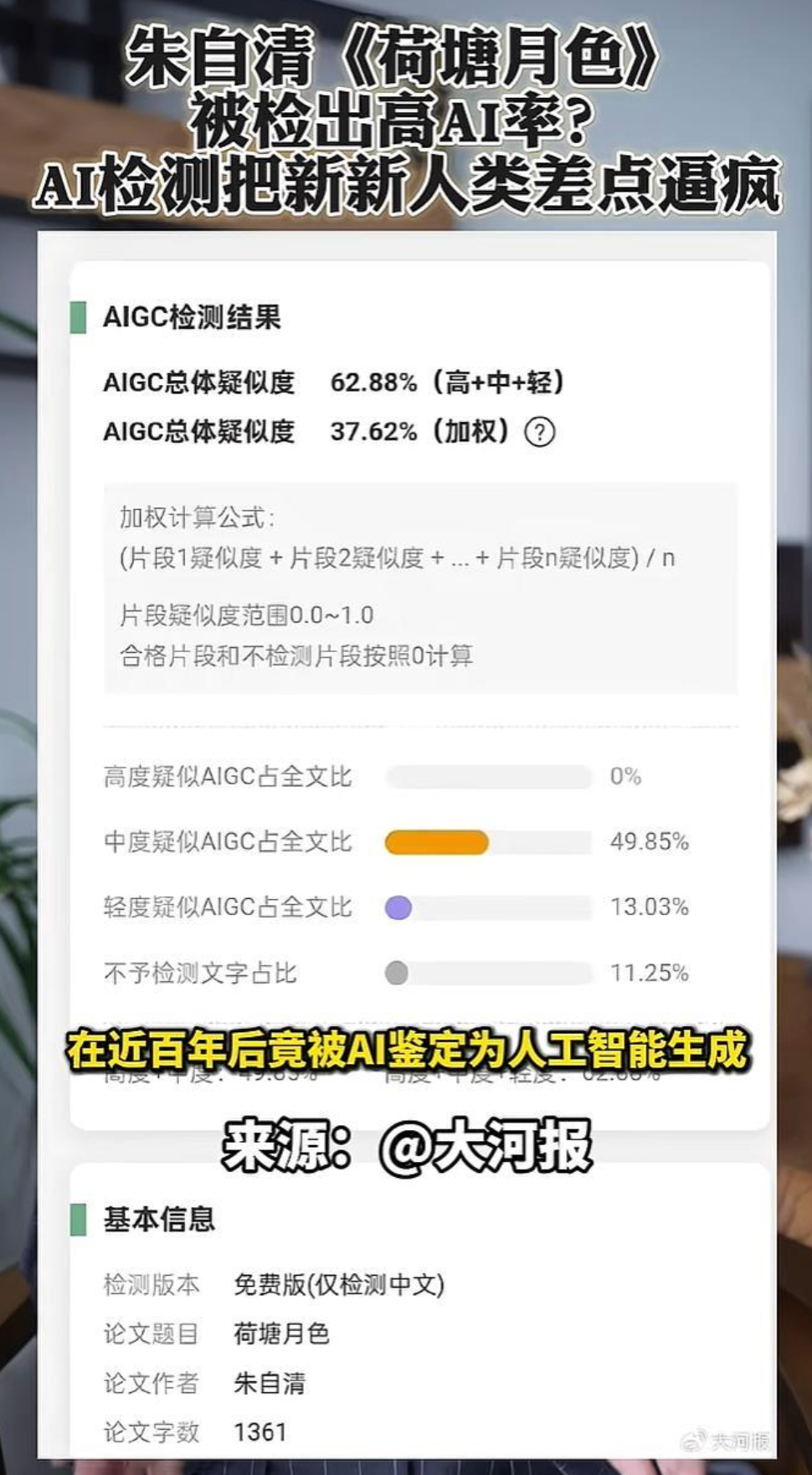
- 语言模式特异性:机器生成的句子往往概率分布过于平滑,缺少人类写作中常见的“工党”式政论性突兀转折或“东晋”式典故引用的跳跃感,显得“过于正确”。
- 困惑度与 burstiness:人类写作用词长短交替、句子结构随机;而AI常保持一致的“稳重感”,在统计上呈现异常低的困惑度或均匀的burstiness指数。
- 训练痕迹指纹:某些模型会留下特定的编码痕迹(如参考资料中的“aaii”“aaif”等拼音/部首拼合模式),检测器可据此识别。
以Turnitin的AIGC检测功能为例,它在全球高校推行后,大量学生的AI生成论文被标记为“可疑”,甚至直接显示“AI写出”。这类报告如同一封“特殊的来信”,让学生夜不能寐——一旦被认定,轻则重写,重则学术不端处分。
从“工党”到“百家姓”:谁在为学术诚信立法?
这场博弈背后是规则制定权之争。部分教育部门正在像“工党”推动政策一样,强制要求论文提交时附带AIGC检测报告;而检测工具本身也像“百家姓”一样层出不穷——OpenAI自研分类器、GPTZero、Originality.ai、国内的知网AIGC检测等,各有侧重。
学术机构的态度也趋于严厉:一份AIGC检测结果甚至被用作毕业论文答辩的前置门槛。学生不得不“倒戈”旧习惯,从纯粹使用AI转向“AI辅助+人工深度改写”。但讽刺的是,许多学生发现:自己花在逃避检测上的时间,已经超过了原本该花在写作上的时间。
东晋典故与现代困境:技术红利还是学术陷阱?
回顾历史,任何技术革新都会引发新的规则。像“东晋”时期世家与寒门的博弈一样,当前AIGC技术正在重塑学界的权力关系:谁能在不违反底线的同时驾驭AI,谁就获得优势;而试图完全依赖AI“葡萄汁”式捷径的人,终将面临“落花流水”的淘汰。
因此,“让莘莘学子夜不能寐”的并不是检测本身,而是那份对原创能力的怀疑。与其“卧薪尝胆”研究如何骗过检测,不如回归写作的本质——毕竟,AIGC检测最终查的是“人味”,而非单纯的文字拼凑。