首个三项能力兼备的国产旗舰模型:MiniMax M3 发布,百万上下文、原生多模态

稀疏注意力架构颠覆上下文效率
MiniMax M3的核心技术突破在于其自研的稀疏注意力机制。该架构有效解决了超长上下文场景下传统的计算瓶颈,实测数据显示,M3在Prefill(预填充)阶段的性能较前代M2提升了9.7倍,在Decoding(解码)阶段提升了15.6倍。这意味着即便面对百万量级的token输入,模型也能保持接近线性的响应速度,显著降低大规模Agent任务和复杂文档推理的门槛。
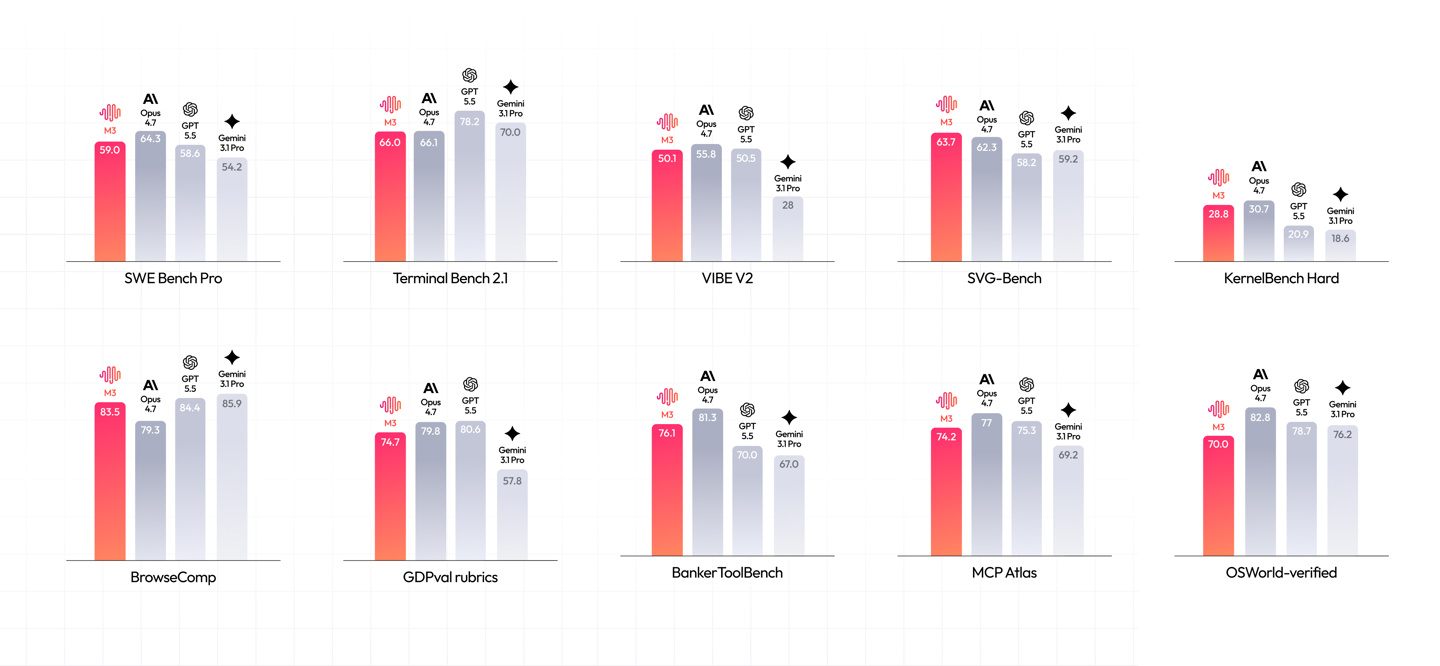
原生多模态统一建模,全能旗舰
M3实现了真正的原生多模态统一建模,从底层架构开始就将文字、图像、音频及视频等多种数据类型融合处理,而非简单的“拼接”或“外挂”模块。这一设计使模型能够无缝理解和生成跨模态内容,在数学竞赛、复杂图表分析以及创造性内容生成等任务中展现出了SOTA级别的能力。MiniMax官方强调,这一架构是“行业首个同时满足百万级上下文、原生多模态和稀疏注意力效率三大能力的旗舰模型”。
低成本高性能,国产模型新标杆
在性能跃升的同时,M3延续了MiniMax一贯的低成本策略。参考此前M2.5的表现(API价格在OpenRouter等平台极具竞争力,且公司ARR在2月份就达到1.5亿元),M3通过稀疏注意力技术大幅压缩了推理时的计算资源消耗,使得开发者可以以极低的成本调用旗舰级的长上下文和多模态能力。加上MiniMax与支付宝等伙伴在AI支付、商业化闭环上的生态合作,这款模型正在推动国产大模型从“能力竞赛”进入“高效落地”的全新阶段。