MiniMax发布新模型M3,竞争转向长上下文与Agent能力

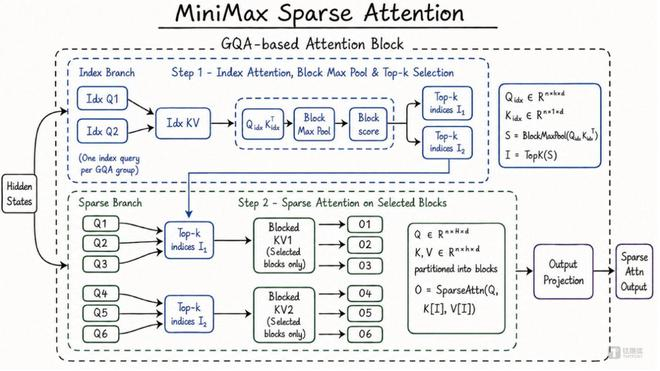
1M超长上下文加持,MSA架构将推理成本砍至1/20
M3搭载了自研的MiniMax Sparse Attention(MSA)稀疏注意力架构,这一技术突破直接将模型上下文窗口扩展至100万Token。相比传统的全注意力机制,MSA能在长文档、复杂代码仓库、多轮任务协作等场景下保留更完整的信息链路,同时将单Token计算量压缩至上一代模型的约1/20。这意味着在100万Token规模下,推理效率实现量级跃升,为Agent类应用铺平了“更长上下文、更稳定记忆、更低成本推理”的路径。业界认为,这已成为衡量下一阶段大模型可用性的核心标尺。
智能体编程能力国际领先,模拟真实开发者协作训练
M3在Coding与Agentic能力上实现代际突破,SWE-Bench Pro得分59.0%、Terminal Bench 2.1高达66.0%,在软件工程、终端执行、效率与协议理解等多个国际权威评测中均达领先水平。其训练创新引入了交互式用户模拟器框架,让模型在训练阶段就接触接近真实生产环境的开发者协作场景。作为搭配M3的首选Agent产品,MiniMax Code同步更新,能将大型任务拆解为多阶段、可并发、可动态调整的Workflow,由Agent集群协作推进,实现长程复杂任务的自动化执行。
原生多模态直通物理世界,桌面操作能力突破
M3从训练起点便采用文本、图片、视频等多模态混合训练,并且是“从Step 0开始”进行多模态混合训练的模型。交错数据(Interleaved data)被证明对性能提升至关重要,MiniMax为此重构数据管线后,将训练数据Token规模提升至100万亿量级。模型不仅支持图像与视频理解,还具备桌面操作能力(Computer Use),可在复杂跨应用环境中执行任务——意味着AI正在从语言理解层走向真实的数字环境执行层,办公自动化、企业软件操作等场景的落地速度明显加快。
取消缓存写入费,订阅计划面向专业开发者
商业化方面,MiniMax推出了Token Plan订阅方案:Plus版每月49元(6亿Token)、Max版每月119元(18亿Token)、Ultra版每月469元(55亿Token)。值得注意的是,MiniMax已正式取消了此前备受争议的“缓存写入”费用,这让开发者在Agent及RAG场景下的试错门槛大幅降低,定价策略向国际主流看齐。业内人士分析,M3以“开源+多能力合一”的差异化定位,填补了国内AI生态的空白,其综合能力组合正硬刚国际顶尖模型在编程与Agent领域的护城河。